P1_RC_GGL: test di chiusura rigoroso della dinamica galattica e del lensing debole (curve di rotazione + GGL)
Quadro EFT della gravità media vs. baseline minima NFW per la materia oscura fredda (DM)
Consulta il rapporto di valutazione originale:
1. ChatGPT: https://chatgpt.com/share/6a00cd62-6e34-83eb-b165-6ec09e3519cc
2. Gemini: https://gemini.google.com/share/773ec96d75a0
3. Grok: https://grok.com/share/bGVnYWN5LWNvcHk_c0b4fa65-0e86-4adb-9b58-5617d616dc04
4. Qwen: https://chat.qwen.ai/s/22ab9336-671f-420a-a7fa-43e24774bb2a?fev=0.2.46
5. DeepSeek: https://chat.deepseek.com/share/tj6k7hb5owtoldg2bm
0 Sintesi esecutiva
Questo rapporto è un’edizione d’archivio di livello pubblicabile depositata su Zenodo. Offre una catena integrata e verificabile che copre i dati, il registro dei modelli, il confronto equo, il test di chiusura e i materiali di riproducibilità. L’Appendice B (P1A) funge da supplemento di robustezza. Si concentra su stress test con una “baseline DM più standard + una sistematica chiave di lensing”, usati per valutare la sensibilità delle conclusioni principali a una modellizzazione DM più realistica e al trattamento delle sistematiche del lensing.
Conclusioni principali (quattro affermazioni citabili direttamente; si veda la Sezione 2.4):
(1) Nel fitting delle curve di rotazione (RC), la famiglia EFT supera in modo significativo DM_RAZOR in tutte le combinazioni kernel/prior; il miglioramento tipico è Δlog𝓛_RC ≈ 10^3 (si veda la Tabella S1a).
(2) Nel test di chiusura RC→GGL, EFT mostra una trasferibilità più forte tra sonde: la forza di chiusura Δlog𝓛_closure (True−Perm) è significativamente più alta di quella di DM_RAZOR, e la differenza resta robusta rispetto a covariance shrinkage, scansioni di R_min e di σ_int (si vedano Fig. S3 e Tabella S1b).
(3) Nel fit congiunto (RC+GGL), EFT mantiene un vantaggio stabile; sotto il controllo negativo che rompe la mappatura condivisa, tale vantaggio collassa, sostenendo l’interpretazione secondo cui l’“effetto di gravità media” deriva dalla mappatura condivisa e non da un fit accidentale (si veda Fig. S4).
(4) Senza aumentare sostanzialmente la dimensionalità, l’Appendice B (P1A) sottopone il lato DM a stress test con moduli di baseline DM più standard e una nuisance chiave per le sistematiche del lensing. Questi miglioramenti non eliminano il vantaggio di chiusura di EFT (si vedano Tabella B1 e Fig. B1).
Disponibilità di dati e codice: Concept DOI del rapporto 10.5281/zenodo.18526334; Concept DOI del pacchetto completo di riproduzione 10.5281/zenodo.18526286. I tag corrispondenti all’Appendice B (P1A) sono run_tag=20260213_151233, closure_tag=20260213_161731 e joint_tag=20260213_195428.
1 Riassunto
Conduciamo un confronto quantitativo riproducibile tra due quadri teorici usando gli stessi dati e lo stesso protocollo statistico: il modello di “correzione della gravità media” proposto dalla Teoria del filamento di energia (Energy Filament Theory, EFT; da non confondere con la comune abbreviazione di effective field theory) e un modello baseline di alone NFW di materia oscura fredda (DM_RAZOR). DM_RAZOR è scelto deliberatamente come “baseline DM minima”: un alone NFW con relazione c–M fissa (senza dispersione da alone ad alone), usato come controllo verificabile e riproducibile. Va inoltre sottolineato che questo articolo tratta EFT come una parametrizzazione fenomenologica, di tipo MOND, di campo efficace/risposta efficace da testare entro un protocollo statistico unificato, e non come una derivazione dei suoi primi principi microscopici all’interno di questo lavoro.
I dati comprendono 2.295 punti di velocità provenienti dalle curve di rotazione SPARC (RC), preprocessati e binning uniforme (104 galassie, 20 bin RC), insieme alla densità superficiale in eccesso ΔΣ(R) del lensing debole galassia-galassia (GGL) KiDS-1000 (4 bin di massa stellare × 15 punti R per bin, 60 punti totali, usando la covarianza completa).
Eseguiamo in sequenza inferenza RC-only, un test di chiusura RC→GGL, inferenza GGL-only e inferenza congiunta RC+GGL, usando audit di coerenza per garantire che ogni valore numerico citato sia tracciabile. Sotto un rigoroso registro dei parametri e vincoli di mappatura condivisa (DM: 20 parametri log M200_bin; EFT: 20 parametri log V0_bin + 1 log ℓ globale), la famiglia EFT supera significativamente DM_RAZOR nel fit congiunto: ΔlogL_total = 1155–1337 rispetto a DM_RAZOR. Ancora più importante, il test di chiusura mostra che il posteriore RC possiede una potenza predittiva non banale per GGL: la forza di chiusura di EFT è ΔlogL_closure = 172–281, superiore al valore 127 di DM_RAZOR. Quando il raggruppamento RC-bin→GGL-bin viene rimescolato casualmente, il segnale di chiusura collassa a 6–23, confermando che il segnale non è un accidente statistico né un artefatto di implementazione. Attraverso scansioni sistematiche di σ_int, R_min e covariance shrinkage, il vantaggio relativo di EFT resta positivo e stabile in ampiezza. Per rispondere alle preoccupazioni comuni secondo cui la “baseline DM sarebbe troppo debole” o le “sistematiche sarebbero scambiate per fisica”, l’Appendice B (P1A) fornisce uno stress test della baseline DM più standard ma ancora a bassa dimensionalità e verificabile, includendo dispersione c–M gerarchica + prior, un proxy core a un parametro, lensing m e il modello combinato DM_STD. Sotto lo stesso protocollo di chiusura, questi miglioramenti non eliminano il vantaggio di chiusura di EFT (si vedano Tabella B1/Fig. B1).
Parole chiave: curve di rotazione; lensing debole galassia-galassia; test di chiusura; EFT; materia oscura fredda; inferenza bayesiana
2 Introduzione e panoramica dei risultati
Le curve di rotazione (RC) e il lensing debole galassia-galassia (GGL) sono due sonde gravitazionali complementari: le RC vincolano il potenziale dinamico e la relazione di accelerazione radiale (RAR) nel piano del disco, mentre il GGL misura la distribuzione di massa proiettata e la risposta gravitazionale su scala di alone. Per qualunque teoria candidata, la questione decisiva non è se riesca a fittare separatamente i due dataset, ma se riesca a spiegarli in modo coerente sotto la stessa mappatura tra dati e gli stessi vincoli condivisi.
Di conseguenza, questo articolo assume il “test di chiusura” come protocollo statistico centrale: prima si usa il posteriore RC-only per predire in avanti il GGL, poi lo si confronta con un controllo negativo in cui la mappatura RC-bin→GGL-bin viene permutata/rimescolata. Ciò valuta la trasferibilità predittiva tra dataset ed esclude falsi segnali dovuti a bias di implementazione o fitting accidentale.
Posizionamento teorico e ambito: questo articolo non cerca di presentare una derivazione microscopica da primi principi di EFT (Teoria del filamento di energia, Energy Filament Theory) né una formulazione relativisticamente completa. Trattiamo invece EFT come una parametrizzazione a bassa dimensionalità, di tipo MOND, di campo efficace/risposta efficace (descritta da un kernel f(x) e da una scala globale ℓ), e ne testiamo la coerenza tra dataset e la potenza predittiva trasferibile tramite il test di chiusura RC→GGL sotto un rigoroso registro dei parametri.
Programma di ricerca e dichiarazione di ambito: questo articolo fa parte di un programma osservativo di retrieval della serie P tuttora in corso. Nei dati esistenti su scala galattica cerchiamo due possibili contributi efficaci di fondo: (i) un “pavimento di gravità media” descrivibile da una risposta gravitazionale media coarse-grained, e (ii) un “pavimento stocastico/di rumore” associato alle fluttuazioni dei processi microscopici. In questo articolo (P1) ci concentriamo solo sul primo: senza introdurre alcuna ipotesi sui meccanismi microscopici di produzione, usiamo il test di chiusura RC→GGL per recuperare indicazioni osservative di un pavimento di gravità media e confrontarlo con una baseline DM verificabile sotto un protocollo di controllo unificato. Come immagine fisica euristica, se esistono gradi di libertà a vita breve, il loro decadimento/annichilazione può convertire massa a riposo in energia-impulso trasportati da altri gradi di libertà, corrispondendo naturalmente, a livello efficace, a una decomposizione “contributo medio + contributo fluttuante”; tuttavia, questo articolo non modella quantitativamente tale quadro microscopico.
Per evitare sovrainterpretazioni, i confini di ambito di questo articolo sono i seguenti:
• Cosa fa questo articolo: sotto vincoli rigorosi di registro dei parametri e mappatura condivisa, usa test di chiusura per misurare la trasferibilità predittiva tra dataset ed esegue un confronto riproducibile tra la risposta di gravità media EFT e una baseline DM.
• Cosa non fa questo articolo: non discute meccanismi microscopici di produzione, abbondanze/vite medie o vincoli cosmologici; non modella il termine stocastico corrispondente al “pavimento di rumore”.
• Cosa non afferma questo articolo: non mira a rovesciare la materia oscura; P1 non emette un verdetto finale sull’esistenza di un “pavimento”, ma riporta evidenza a livello di fase: entro il dominio di misura robusto selezionato qui, i dati favoriscono modelli che includono una risposta gravitazionale media.
Al tempo stesso, chiariamo che DM_RAZOR rappresenta soltanto una baseline NFW minima e verificabile (c–M fisso e nessuna dispersione; nessuna contrazione adiabatica, core da feedback, non sfericità o termini ambientali). Pertanto, la conclusione principale del testo è strettamente limitata a questa affermazione: sotto la baseline minima e vincoli rigorosi di registro/mappatura dei parametri, EFT mostra una coerenza tra dataset più forte. Per rispondere alla domanda comune se una baseline ΛCDM più standard e una modellizzazione delle principali sistematiche del lensing cambierebbero sostanzialmente la conclusione, raccogliamo miglioramenti DM più standard ma ancora a bassa dimensionalità e verificabili, insieme a una nuisance lato lensing, nell’Appendice B (P1A: stress test di standardizzazione della baseline DM), mantenendo esattamente la stessa mappatura condivisa e lo stesso protocollo di test di chiusura del testo principale (si vedano Tabella B1/Fig. B1).
2.1 Tab. S1a–S1b: sintesi delle metriche chiave (rigorosa)
La Tabella S1a riporta le principali metriche di confronto per il fit congiunto (RC+GGL): logL, ΔlogL, AICc e BIC. La Tabella S1b riporta le metriche del test di chiusura e delle scansioni di robustezza: chiusura, controllo negativo con shuffle e intervalli di scansione σ_int / R_min / cov-shrink. Tutti i valori provengono dalla tabella master rigorosa Tab_Z1_master_summary e possono essere tracciati voce per voce nel pacchetto d’archivio della release.
Tabella S1a | Metriche principali del confronto nel fit congiunto (RC+GGL, rigoroso).
Modello (workspace) | Kernel W | k | logL_total congiunto (best) | ΔlogL_total vs DM | AICc | BIC |
DM_RAZOR | none | 20 | -16927.763 | 0.0 | 33895.885 | 34010.811 |
EFT_BIN | none | 21 | -15590.552 | 1337.21 | 31223.501 | 31344.155 |
EFT_WEXP | exponential | 21 | -15668.83 | 1258.932 | 31380.057 | 31500.711 |
EFT_WYUK | yukawa | 21 | -15772.936 | 1154.827 | 31588.268 | 31708.922 |
EFT_WPOW | powerlaw_tail | 21 | -15633.321 | 1294.442 | 31309.038 | 31429.692 |
Tabella S1b | Metriche di chiusura e robustezza (rigorose).
Modello (workspace) | Chiusura ΔlogL (true-perm) | ΔlogL del controllo negativo dopo shuffle | Intervallo ΔlogL scansione σ_int | Intervallo ΔlogL scansione R_min | Intervallo ΔlogL scansione cov-shrink |
DM_RAZOR | 126.678 | 22.725 | — | — | — |
EFT_BIN | 231.611 | 14.984 | 459–1548 | 1243–1289 | 1337–1351 |
EFT_WEXP | 171.977 | 6.04 | 408–1471 | 1169–1207 | 1259–1277 |
EFT_WYUK | 179.808 | 14.688 | 380–1341 | 1065–1099 | 1155–1166 |
EFT_WPOW | 280.513 | 6.672 | 457–1500 | 1203–1247 | 1294–1308 |
2.2 Fig. S3: forza di chiusura (RC-only → GGL predetto)
La forza di chiusura è definita come ΔlogL_closure ≡ ⟨logL_true⟩ − ⟨logL_perm⟩: sui campioni posteriori RC-only, il GGL viene predetto in avanti e confrontato con un controllo negativo in cui la mappatura RC-bin→GGL-bin è permutata.
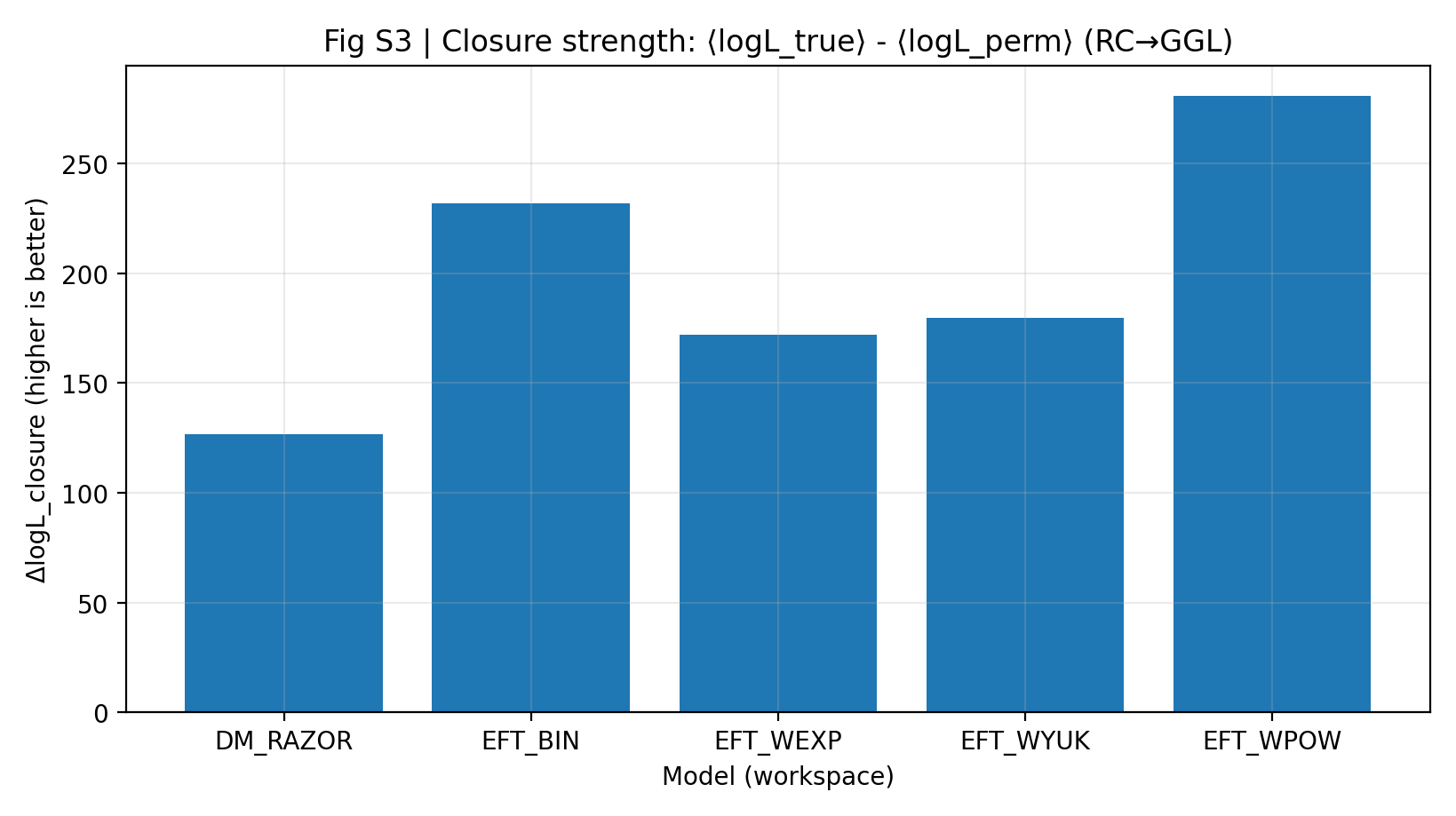
Fig. S3 | Forza di chiusura (più alto è meglio): vantaggio medio di log-verosimiglianza della previsione RC-only → GGL.
2.3 Fig. S4: confronto principale del fit congiunto (RC+GGL)
Il vantaggio del fit congiunto è definito come ΔlogL_total ≡ logL_total(model) − logL_total(DM_RAZOR). Con gli stessi dati, la stessa mappatura e una scala di parametri quasi identica, la famiglia EFT raggiunge una log-verosimiglianza congiunta significativamente più alta.
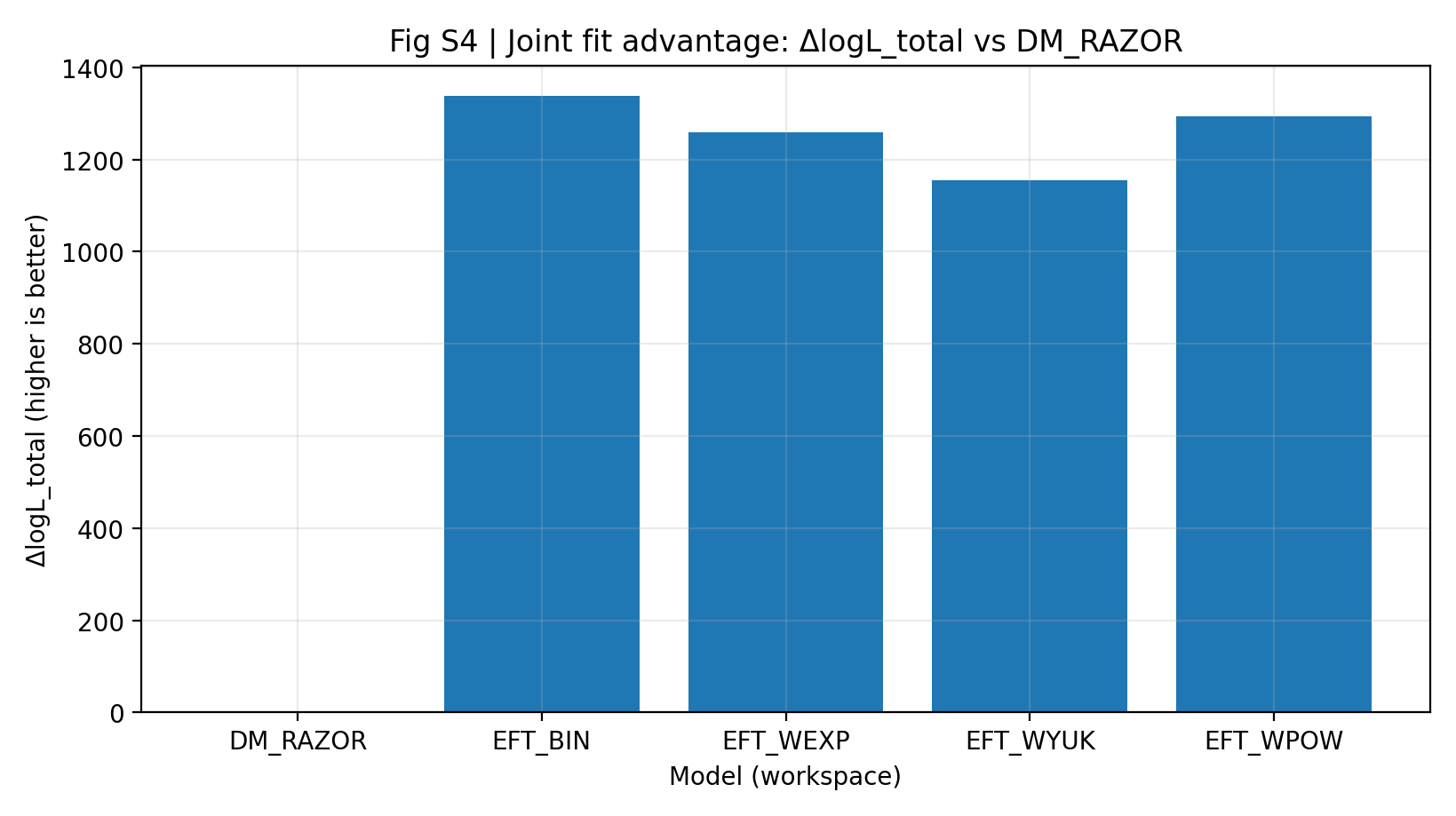
Fig. S4 | Vantaggio del fit congiunto (più alto è meglio): miglior logL_total per RC+GGL rispetto a DM_RAZOR.
2.4 Quattro conclusioni (citabili direttamente)
(1) In un’analisi congiunta unificata delle curve di rotazione SPARC e del lensing debole KiDS-1000, il modello del quadro EFT di gravità media supera sistematicamente DM_RAZOR sotto un protocollo di controllo rigoroso: ΔlogL_total = 1155–1337 rispetto a DM_RAZOR.
(2) Il test di chiusura RC→GGL mostra una coerenza predittiva più forte per EFT: ΔlogL_closure = 172–281, contro 127 per DM_RAZOR. Quando il raggruppamento RC-bin→GGL-bin viene rimescolato casualmente, il segnale di chiusura collassa a 6–23, indicando che il segnale dipende dalla corretta mappatura tra dataset e non da fitting accidentale.
(3) Le scansioni sistematiche di σ_int, R_min e covariance shrinkage non cambiano né il segno né la scala di “EFT supera DM_RAZOR”, indicando che la conclusione è robusta rispetto a perturbazioni sistematiche comuni.
(4) Sotto lo stesso protocollo di chiusura, l’Appendice B (P1A) rafforza la baseline DM in modo “standardizzato e verificabile”: conserva tre miglioramenti a un parametro (SCAT/AC/FB) e aggiunge dispersione c–M gerarchica + prior, un proxy core a un parametro e una calibrazione di shear m lato lensing (più il loro modello combinato DM_STD). I risultati mostrano che solo il ramo feedback/core porta un piccolo miglioramento netto della forza di chiusura (122.21→129.45, ΔΔlogL_closure≈+7.25); gli altri miglioramenti contribuiscono in modo trascurabile o negativo alla forza di chiusura. Dunque, la conclusione principale non dipende dal fatto che DM_RAZOR sia una baseline eccessivamente debole.
3 Dati e preprocessing
Questo studio usa due dataset pubblici. Nel workflow ingegneristico, download, verifica checksum (sha256) e preprocessing sono completati con script tracciabili. Per garantire un confronto equo tra modelli, tutti i workspace (EFT_BIN / EFT_WEXP / EFT_WYUK / EFT_WPOW / DM_RAZOR) condividono esattamente gli stessi prodotti dati e le stesse mappature dei bin.
3.1 Curve di rotazione (RC, SPARC)
I dati RC provengono dai file Rotmod_LTG del database SPARC (175 file rotmod). Dopo il preprocessing, il campione di modellizzazione include 104 galassie e 2.295 punti dati (r, V_obs), divisi in 20 bin RC in base alla massa stellare e a criteri correlati. Ogni punto dati contiene raggio r (kpc), velocità osservata V_obs (km/s), errore osservativo σ_obs e velocità delle componenti gas/disco/bulge (V_gas, V_disk, V_bul).
3.2 Lensing debole (GGL, KiDS-1000 / Brouwer+2021)
I dati GGL usano la densità superficiale in eccesso ΔΣ(R) dalla Fig. 3 di Brouwer et al. (2021), basata su KiDS-1000 (4 bin di massa stellare, 15 punti R per bin), insieme alla covarianza completa fornita. Nel workflow ingegneristico, la covarianza originale in formato lungo viene ricostruita in una matrice 15×15 per ciascun bin, e gli audit Stage-B verificano ragionevolezza dimensionale e numerica.
3.3 Mappatura RC-bin → GGL-bin e dimensione totale del campione
I 4 bin di massa GGL e i 20 bin RC sono collegati tramite una mappatura fissa: ogni bin GGL corrisponde a 5 bin RC, e i contributi dei bin RC sono pesati per il numero di galassie. Questa mappatura è mantenuta fissa in tutti i modelli ed è il vincolo centrale per il confronto equo nel test di chiusura e nel fitting congiunto. Il dataset congiunto finale contiene n_total = 2355 punti (RC=2295, GGL=60).
4 Modelli e metodi statistici
4.1 Specifica matematica minima per EFT e DM (verificabile/testabile)
Questa sezione fornisce la specifica matematica minima che mappa direttamente sull’implementazione.
(a) Modello delle curve di rotazione (RC)
Per ciascun punto dati RC (r, V_obs, σ_obs), usiamo la sovrapposizione delle componenti: V_mod²(r) = V_bar²(r) + V_extra²(r). Qui V_bar²(r) = V_gas²(r) + Υ_d·V_disk²(r) + Υ_b·V_bul²(r). I risultati principali di questo articolo adottano Υ_d = Υ_b = 0.5, coerente con le raccomandazioni empiriche SPARC e utile a ridurre gradi di libertà non necessari.
(b) Correzione di gravità media EFT (EFT)
Il termine extra EFT è parametrizzato nella forma di “velocità media al quadrato”: V_extra²(r) = V0_bin² · f(r/ℓ). Qui V0_bin è il parametro di ampiezza per ciascun bin RC (20 parametri), ℓ è una scala globale (1 parametro) e f(x) è una funzione di forma del kernel adimensionale. Le forme di kernel confrontate in questo articolo (nessuna delle quali introduce ulteriori gradi di libertà continui) sono:
- none: f(x)=x/(1+x)
- exponential: f(x)=1−exp(−x)
- yukawa: f(x)=1−exp(−x)·(1+0.5x)
- powerlaw_tail: f(x)=1−(1+x)^(−1/2)
- (controllo opzionale) gaussian: f(x)=erf(x/√2) (non incluso nell’insieme principale di conclusioni)
Motivazione fisica (estesa): EFT interpreta la risposta gravitazionale extra su scala galattica come una risposta efficace ottenuta tramite coarse-graining/media di scala di azioni più microscopiche su scale finite. In questo articolo non assumiamo alcun meccanismo microscopico specifico; usiamo invece una parametrizzazione minima e verificabile per un confronto controllato e un test entro un protocollo statistico unificato.
A livello intuitivo, il termine extra può essere scritto in forma di accelerazione: a_extra(r)=V_extra²(r)/r=(V0_bin²/r)·f(r/ℓ). Quando r≫ℓ, f→1 e V_extra→V0_bin, producendo un contributo di velocità extra approssimativamente piatto nella regione esterna. Quando r≪ℓ e f(x)≈x, può essere introdotta una scala di accelerazione caratteristica a0,bin≈V0_bin²/ℓ (a meno di un fattore O(1) della funzione kernel), fornendo un’intuizione di tipo MOND per la scala di transizione interno-esterno.
La famiglia discreta di kernel usata qui (none/exponential/yukawa/powerlaw_tail) può essere vista come un insieme di proxy a bassa dimensionalità per diverse “pendenze iniziali / velocità di transizione / code a lungo raggio” (per esempio, schermatura di tipo Yukawa contro una risposta con coda più lunga). Sono usati per stress test di robustezza, non per esaurire lo spazio dei modelli. Nella componente di lensing debole, costruiamo una massa e una densità di inviluppo efficaci da V_avg(r), poi le proiettiamo per ottenere ΔΣ(R). Questa densità efficace va intesa come descrizione efficace del potenziale di lensing sotto le ipotesi di simmetria sferica e mappatura di campo debole (i dettagli completi sono spostati in Appendice A).
Tutte le forme di kernel sopra soddisfano f(x)→1 per x→∞ (cioè saturazione V_extra²→V0²), mentre danno crescita lineare o sublineare per x≪1: per esempio, exponential: f≈x; yukawa: f≈0.5x; powerlaw_tail: f≈0.5x. Pertanto, forme di kernel diverse producono differenze osservabili nella “pendenza iniziale” a piccolo raggio, nella velocità di transizione e nella coda esterna, e possono essere distinte dai test congiunti RC+GGL e di chiusura.
La previsione EFT per il lensing debole ΔΣ(R) è ottenuta inferendo massa e densità di inviluppo da V_avg(r), seguite da integrali di proiezione: M_enc(r)=r·V_avg²(r)/G, ρ(r)=(1/4πr²)·dM_enc/dr, Σ(R)=2∫_R^∞ ρ(r)·r/√(r²−R²) dr, e ΔΣ(R)=Σ̄(<R)−Σ(R). L’implementazione numerica usa una griglia logaritmica e la raffina adattivamente nei casi eccezionali per garantire stabilità e riproducibilità.
(c) DM_RAZOR: baseline di alone NFW di materia oscura fredda
Al tempo stesso, chiariamo che DM_RAZOR rappresenta soltanto una baseline NFW minima e verificabile (c–M fisso e nessuna dispersione; nessuna contrazione adiabatica, core da feedback, non sfericità o termini ambientali). Per ridurre il rischio di una “baseline fantoccio”, questo articolo non afferma che tali effetti non esistano. Li incorpora invece nell’Appendice B (P1A) come stress test a bassa dimensionalità e verificabili, includendo il trattamento gerarchico della dispersione c–M, un proxy core e una nuisance di calibrazione shear lato lensing.
4.2 Registro dei modelli e confronto equo (parametri condivisi = definizione di chiusura)
Il numero di parametri nell’insieme principale di confronto è: DM_RAZOR k=20; famiglia EFT k=21 (il parametro extra è il log ℓ globale). Tutti i modelli condividono gli stessi dati RC, gli stessi dati GGL e la stessa covarianza, la stessa mappatura RC-bin→GGL-bin, gli stessi termini barionici e le stesse conversioni di unità. Inoltre, la forma del kernel (none / exponential / yukawa / powerlaw_tail) è una scelta discreta e non introduce alcun parametro continuo aggiuntivo, impedendo che il vantaggio derivi da “un grado di libertà in più”.
4.3 Verosimiglianza, prior e campionatore
La verosimiglianza RC è gaussiana diagonale: σ_eff² = σ_obs² + σ_int². I risultati principali fissano σ_int=5 km/s, e Run-5 scansiona σ_int. La verosimiglianza GGL usa una gaussiana a covarianza completa per ciascun bin: logL_GGL = Σ_b log 𝒩(ΔΣ_obs^b | ΔΣ_mod^b, C_b). L’obiettivo congiunto è logpost(θ)=logprior(θ)+logL_RC(θ)+logL_GGL(θ). I prior codificano principalmente confini fisicamente ammissibili (vincoli di intervallo su log ℓ, log V0 e log M200); quando Υ e σ_int sono liberi, si usano prior debolmente informativi (si vedano l’implementazione e la configurazione del pacchetto di release per i dettagli).
Il campionatore usa una passeggiata casuale Metropolis adattiva a blocchi: ogni passo aggiorna solo un sottoblocco casuale dello spazio dei parametri per migliorare il tasso di accettazione in alta dimensionalità, e la dimensione del passo viene adattata leggermente tramite il tasso di accettazione a finestra (tasso obiettivo circa 0,25). I risultati principali usano la modalità quick (impostazioni come n_steps=800), e ogni workspace produce tracce, residui e grafici PPC per audit manuali e scriptati.
4.4 Test di chiusura e controllo negativo (definizione)
Il test di chiusura (Run-2) verifica se il posteriore RC-only può predire GGL senza rifittare GGL. In concreto, genera in avanti ΔΣ(R) per 4 bin GGL da campioni posteriori RC-only e calcola logL_true con la covarianza completa; quindi permuta casualmente la mappatura di gruppo RC-bin→GGL-bin per ottenere logL_perm. La forza di chiusura è definita come ΔlogL_closure≡⟨logL_true⟩−⟨logL_perm⟩. Inoltre, Run-10 raggruppa casualmente i 20 bin RC in 4×5 (shuffle) e ricalcola la chiusura, testando quanto il segnale di chiusura dipenda dalla mappatura corretta.
5 Risultati principali e interpretazione
5.1 Risultati principali del fit congiunto (RC+GGL)
Il miglior logL_total del fit congiunto e il vantaggio relativo ΔlogL_total (rispetto a DM_RAZOR) sono mostrati nella Tabella S1a e nella Fig. S4. Nell’insieme principale di confronto, EFT_BIN ha il vantaggio congiunto più grande (ΔlogL_total=1337.210), mentre anche le altre forme di kernel EFT mantengono vantaggi significativi (1154.827–1294.442). In base ai criteri informativi (AICc/BIC), la famiglia EFT supera significativamente DM_RAZOR, indicando che il vantaggio non è dovuto a un bias nel numero di parametri.
Nota: il contributo principale a ΔlogL_total≈1337 proviene dal termine RC (ΔlogL_RC≈1065 nella decomposizione congiunta, circa 80%). Lo si può interpretare come un miglioramento modesto, circa Δχ²≈0.90 per punto su N=2295 punti dati RC, che si accumula naturalmente in un vantaggio dell’ordine di 10^3 sotto una verosimiglianza gaussiana diagonale. Al tempo stesso, GGL e il test di chiusura forniscono vincoli indipendenti tra dataset, e il ranking resta stabile sotto stress test di σ_int, R_min e cov-shrink (si vedano Sezione 6 e Tabella S1b).
5.2 Risultati del test di chiusura (RC-only → GGL)
La quantità chiave del test di chiusura, ΔlogL_closure, è riportata nella Tabella S1b e nella Fig. S3. La famiglia EFT ha forze di chiusura pari a 171.977–280.513, superiori al 126.678 di DM_RAZOR. Ciò significa che, senza consentire ulteriori gradi di libertà tra dataset, i campioni posteriori ottenuti da EFT dai dati RC possiedono una potenza predittiva trasferibile più forte per i dati GGL.
Il controllo negativo sostiene ulteriormente la rilevanza fisica del segnale di chiusura: quando il raggruppamento RC-bin→GGL-bin viene rimescolato casualmente, la forza di chiusura di EFT scende a 6–15 (con piccole differenze tra kernel), mentre la forza di chiusura baseline arriva a 172–281. Questo “collasso del segnale” esclude falsi vantaggi causati da implementazione numerica, errori di unità o gestione impropria della covarianza.
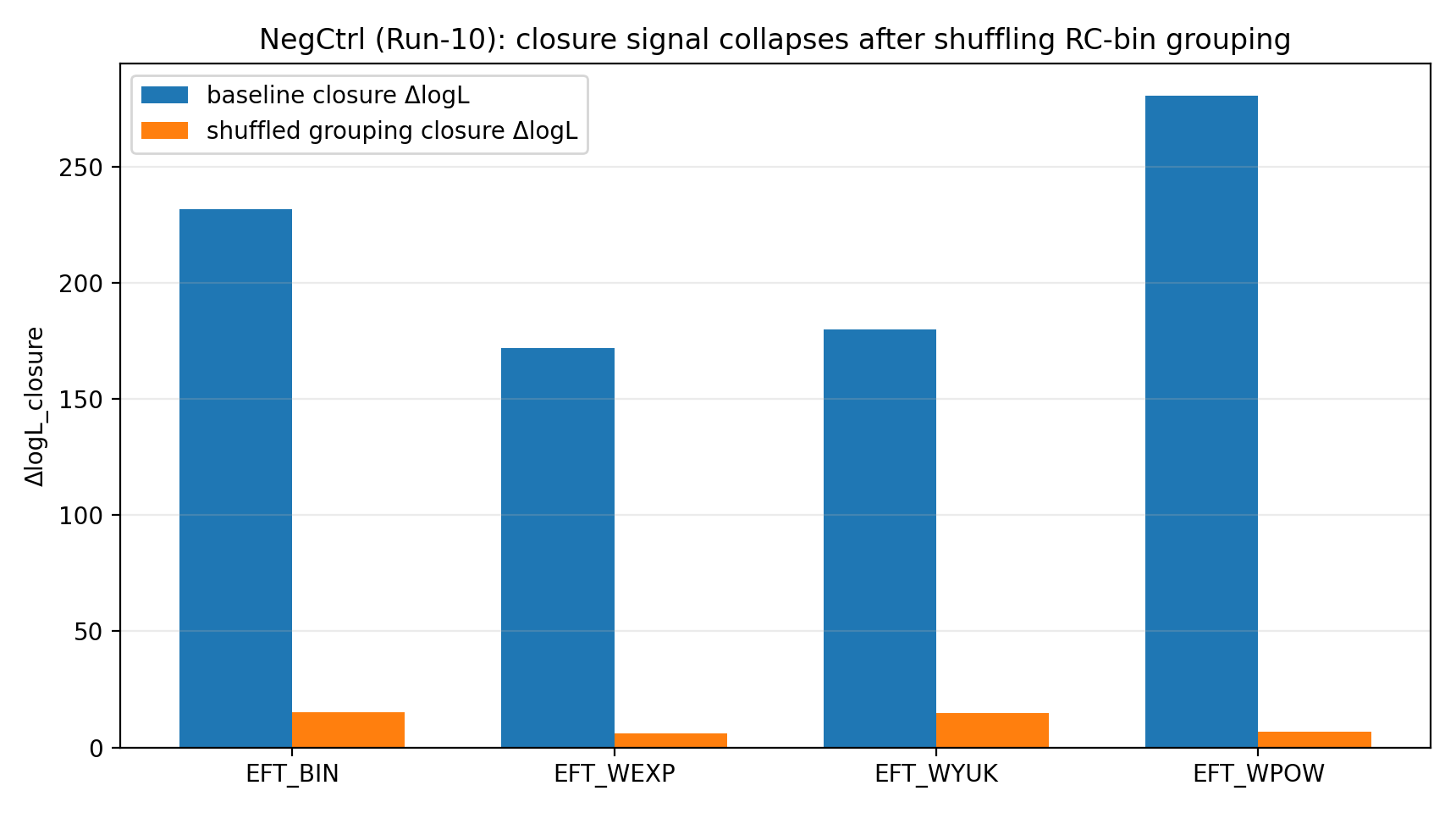
Fig. R1 | Controllo negativo: dopo il raggruppamento shuffle, il segnale di chiusura diminuisce significativamente (tracciato dalle metriche Tab_Z1).
5.3 Significato e limiti dei risultati
La conclusione di questo studio è che “sotto questo dataset e questo protocollo, la correzione di gravità media EFT supera la baseline DM_RAZOR testata”. Va sottolineato che il lato DM usa solo una baseline NFW minima con relazione c(M) fissa, senza formazione di core, non sfericità, termini ambientali o modelli più complessi di connessione galassia-alone. Pertanto, questo manoscritto non afferma di escludere tutte le famiglie di modelli DM. Fornisce invece una baseline di controllo riproducibile, centrata sul test di chiusura, per valutare se RC e GGL possano essere spiegati coerentemente dagli stessi parametri e dalla stessa mappatura tra dataset.
Per rispondere a questa preoccupazione comune, abbiamo completato un progetto di estensione indipendente, P1A (si veda Appendice B). Senza cambiare la mappatura condivisa RC-bin→GGL-bin né il framework di audit, esso rafforza la baseline DM in modo “standardizzato e verificabile”: oltre a tre miglioramenti a un parametro (SCAT/AC/FB), aggiunge ulteriormente (i) dispersione c–M gerarchica + prior massa-concentrazione (DM_HIER_CMSCAT), (ii) un proxy core di feedback barionico a un parametro (DM_CORE1P), e (iii) una nuisance di calibrazione shear lato lensing debole m (DM_RAZOR_M), e riporta un modello combinato DM_STD; EFT_BIN è mantenuto come riferimento di controllo.
• DM_RAZOR_SCAT (dispersione c–M) — introduce il parametro di dispersione della concentrazione da alone ad alone σ_logc per testare se un c(M) fisso sottostimi sistematicamente il potere esplicativo di DM;
• DM_RAZOR_AC (contrazione adiabatica) — usa un singolo parametro α_AC per interpolare continuamente tra “nessuna contrazione” e “contrazione standard”, catturando a costo minimo la tendenza dei barioni a contrarre l’alone interno;
• DM_RAZOR_FB (feedback/core) — usa una scala di core (per esempio, log r_core) per descrivere come la formazione di un core interno sopprima le curve di rotazione, mantenendo l’approssimazione NFW sulle scale di lensing debole.
Lo scoreboard quantitativo P1A è fornito nell’Appendice B, Tabella B1 / Fig. B1 (generato automaticamente da Tab_S1_P1A_scoreboard). Nella metrica di chiusura, DM_RAZOR_FB dà un piccolo miglioramento netto (122.21→129.45, +7.25), mentre gli altri miglioramenti contribuiscono in modo trascurabile o negativo alla forza di chiusura. Sul lato del fit congiunto, aggiungere un prior gerarchico sulla dispersione c–M (DM_HIER_CMSCAT) o il modello combinato (DM_STD) può migliorare sostanzialmente logL congiunto, ma non migliora la forza di chiusura, suggerendo che aggiunga soprattutto flessibilità al fit congiunto piuttosto che trasferibilità tra sonde. Pertanto, la conclusione centrale del testo principale va letta così: sotto vincoli rigorosi di mappatura condivisa e test di chiusura, il vantaggio di coerenza tra dataset di EFT non nasce dalla scelta di una “baseline eccessivamente debole” sul lato DM. Il pacchetto di release P1A corrispondente all’Appendice B (tabelle/figure supplementari e full_fit_runpack) sarà incluso come file aggiuntivo sotto lo stesso Zenodo Concept DOI del full_fit_runpack di questo articolo: https://doi.org/10.5281/zenodo.18526286.
6 Esperimenti di robustezza e controllo
6.1 Scansione σ_int (Run-5)
Scansioniamo sistematicamente la dispersione intrinseca RC σ_int e ripetiamo l’inferenza congiunta a ciascun valore di σ_int, calcolando ΔlogL_total rispetto a DM_RAZOR. I valori minimo/massimo di ΔlogL_total per ciascun modello lungo l’intervallo di scansione sono riportati nella Tabella S1b.
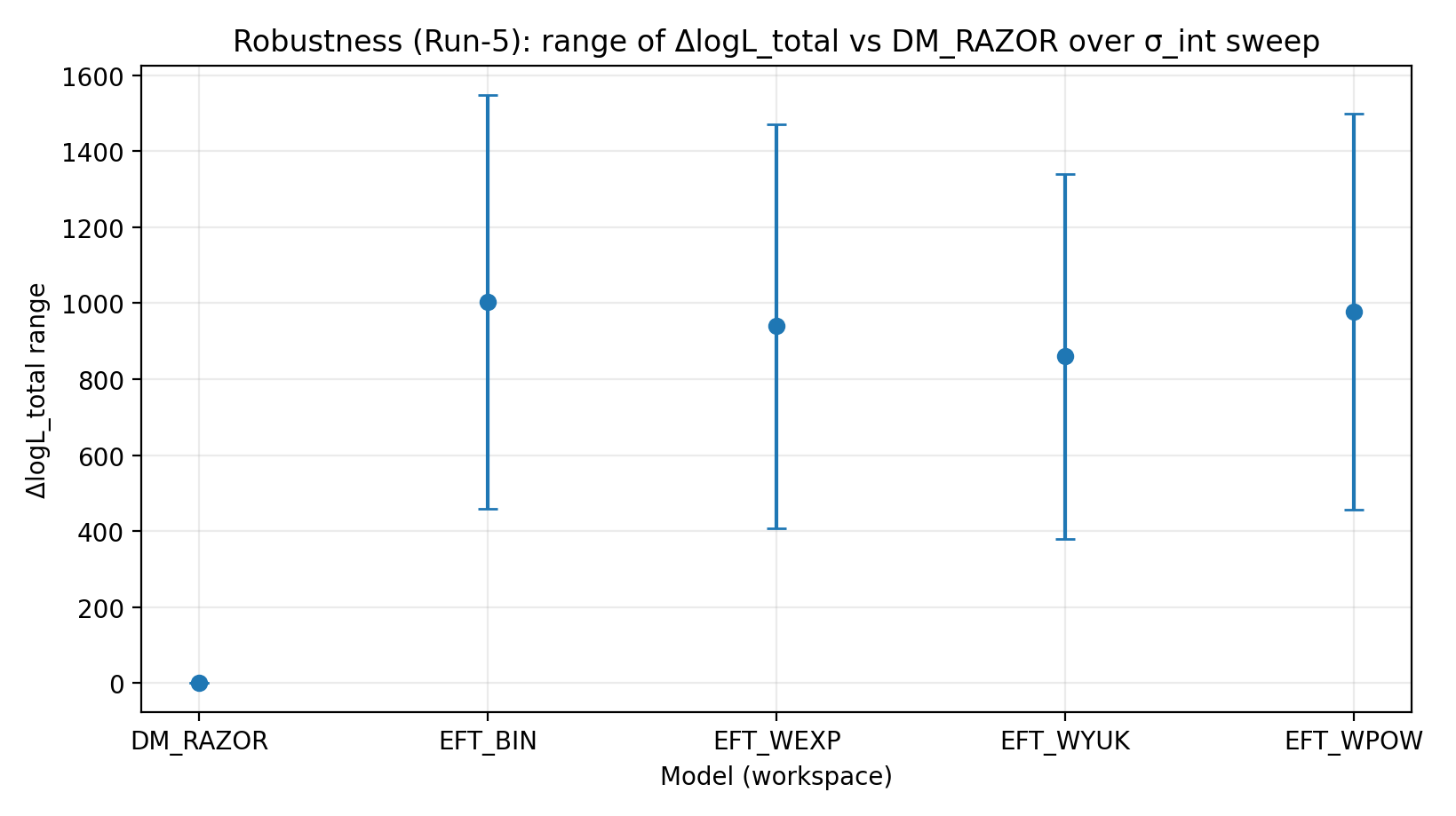
Fig. R2 | Intervallo di ΔlogL_total sotto la scansione σ_int (più alto è meglio).
6.2 Scansione R_min (Run-6)
Per testare l’impatto delle sistematiche nei dati delle regioni centrali (come moto non circolare, risoluzione e modellizzazione barionica insufficiente), applichiamo tagli di soglia R_min alle RC e ripetiamo l’inferenza congiunta. Il vantaggio della famiglia EFT resta positivo e stabile in scala sotto la scansione R_min.
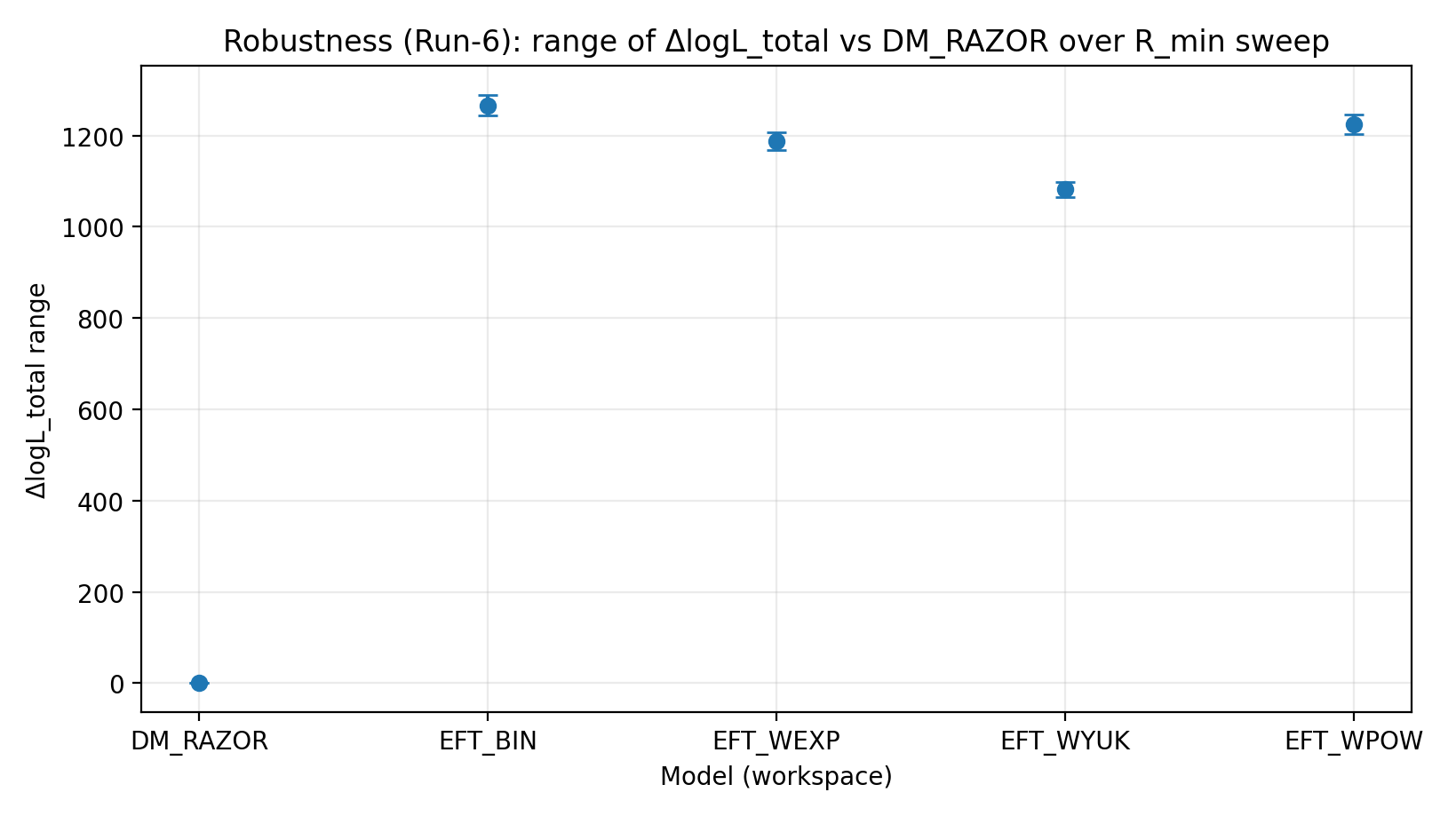
Fig. R3 | Intervallo di ΔlogL_total sotto la scansione R_min (più alto è meglio).
6.3 Scansione cov-shrink (Run-7)
Per testare l’incertezza nella covarianza GGL, applichiamo shrinkage alla matrice di covarianza di ciascun bin di massa: C_α=(1−α)C+α·diag(C), e scansioniamo α. I risultati mostrano che il vantaggio della famiglia EFT è insensibile a questo trattamento.
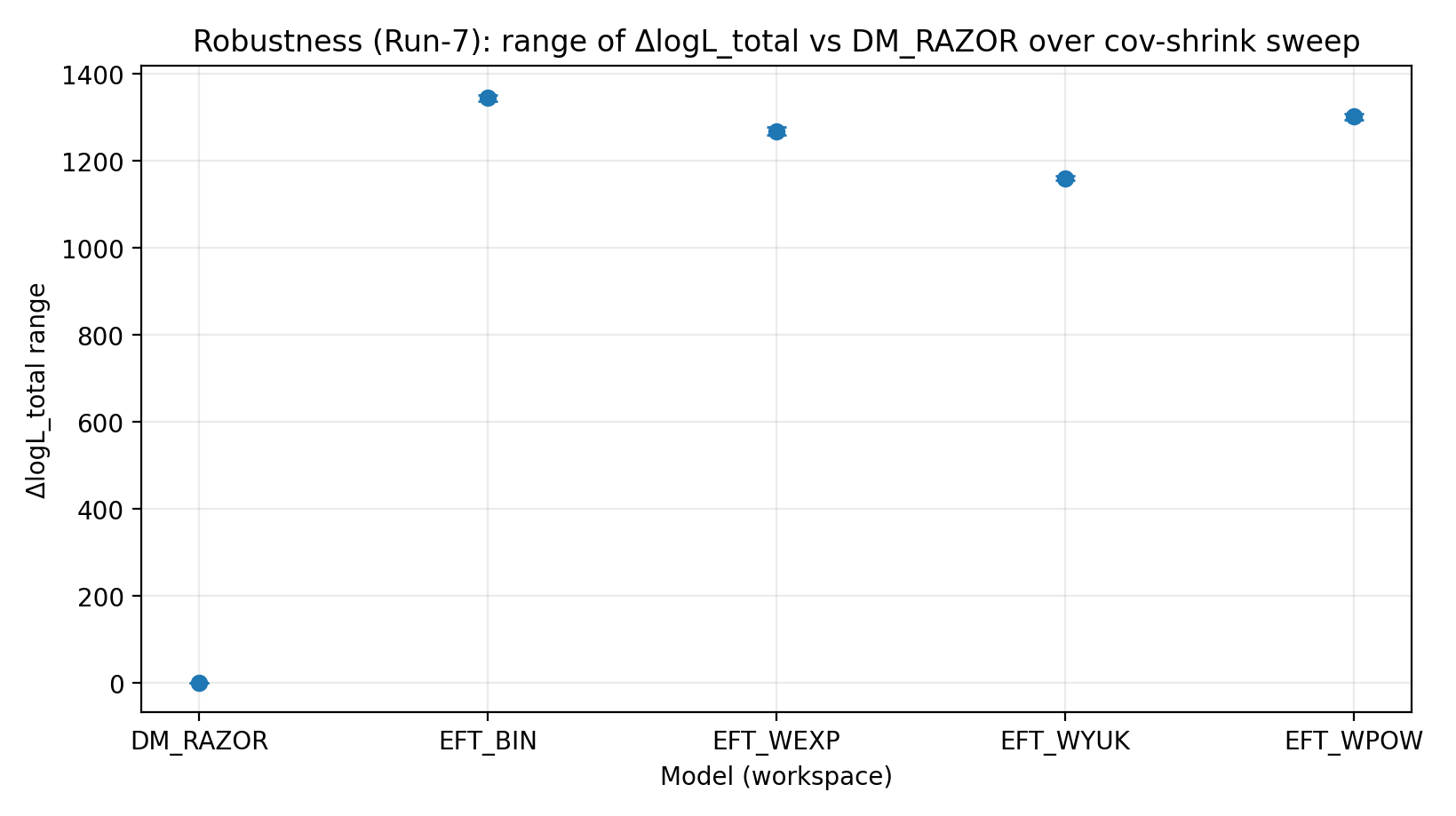
Fig. R4 | Intervallo di ΔlogL_total sotto la scansione cov-shrink (più alto è meglio).
6.4 Scala di ablazione (Run-8)
All’interno di EFT_BIN eseguiamo ablazioni annidate: da un modello minimo (senza parametri liberi), a versioni che conservano solo un piccolo numero di gradi di libertà, fino al modello completo con ampiezza a 20 bin + scala globale. AICc/BIC mostrano che il modello completo EFT_BIN è fortemente richiesto dai dati.
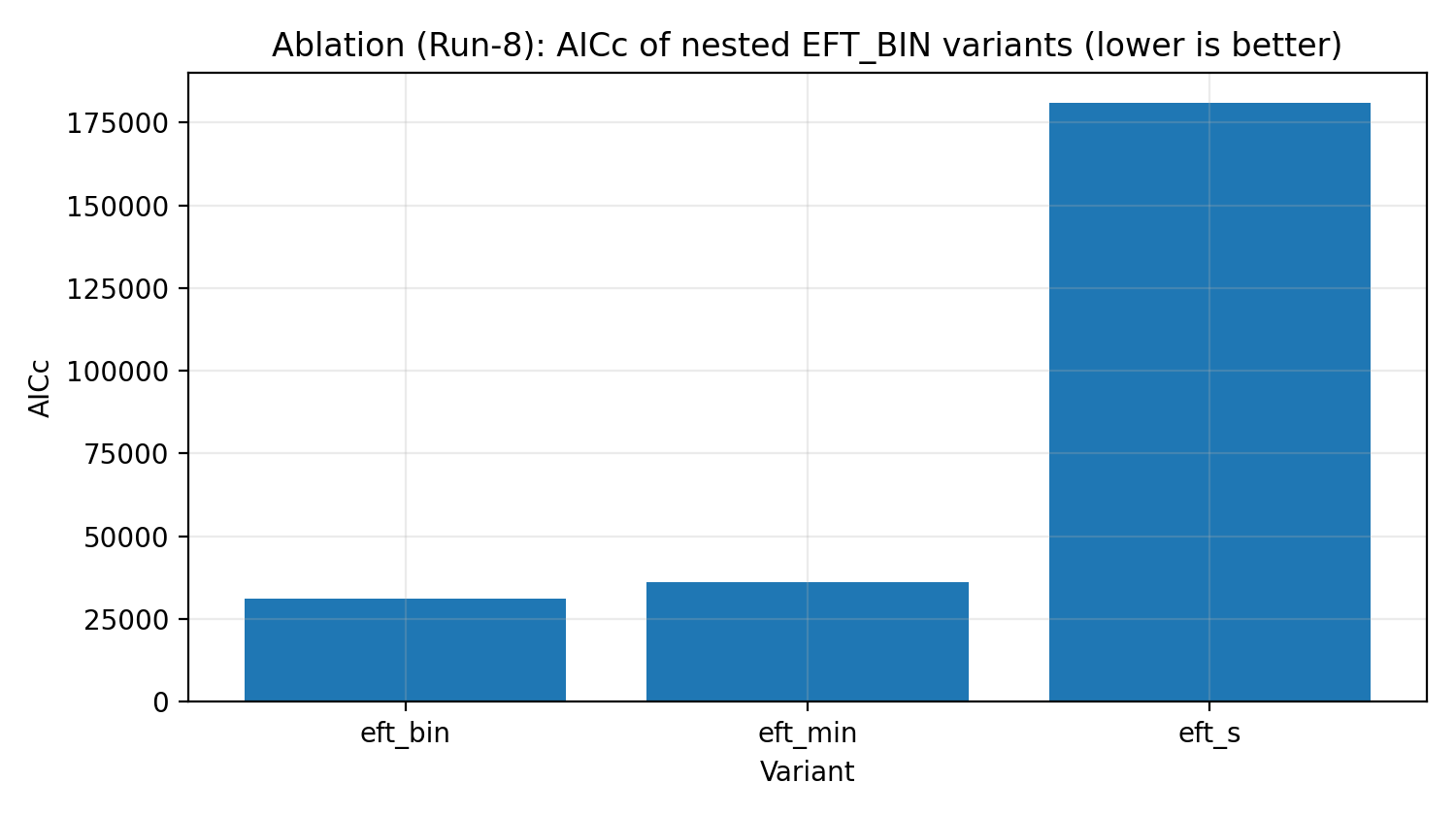
Fig. R5 | Scala di ablazione EFT_BIN (AICc; più basso è meglio).
6.5 Predizione holdout (Run-9)
Eseguiamo inoltre un test leave-one-bin-out (LOO): tra i 4 bin di massa GGL, un bin viene trattenuto ogni volta; l’inferenza viene rifatta usando i bin rimanenti (e tutte le RC), quindi la log-verosimiglianza di test viene valutata sul bin trattenuto. Le metriche riassuntive sono fornite nella tabella supplementare Tab_R3_leave_one_bin_out (un prodotto Run-9; i pattern dei percorsi file sono elencati nella lista dei prodotti chiave della Sezione 8.2). La famiglia EFT resta chiaramente superiore a DM_RAZOR anche nel caso holdout peggiore.
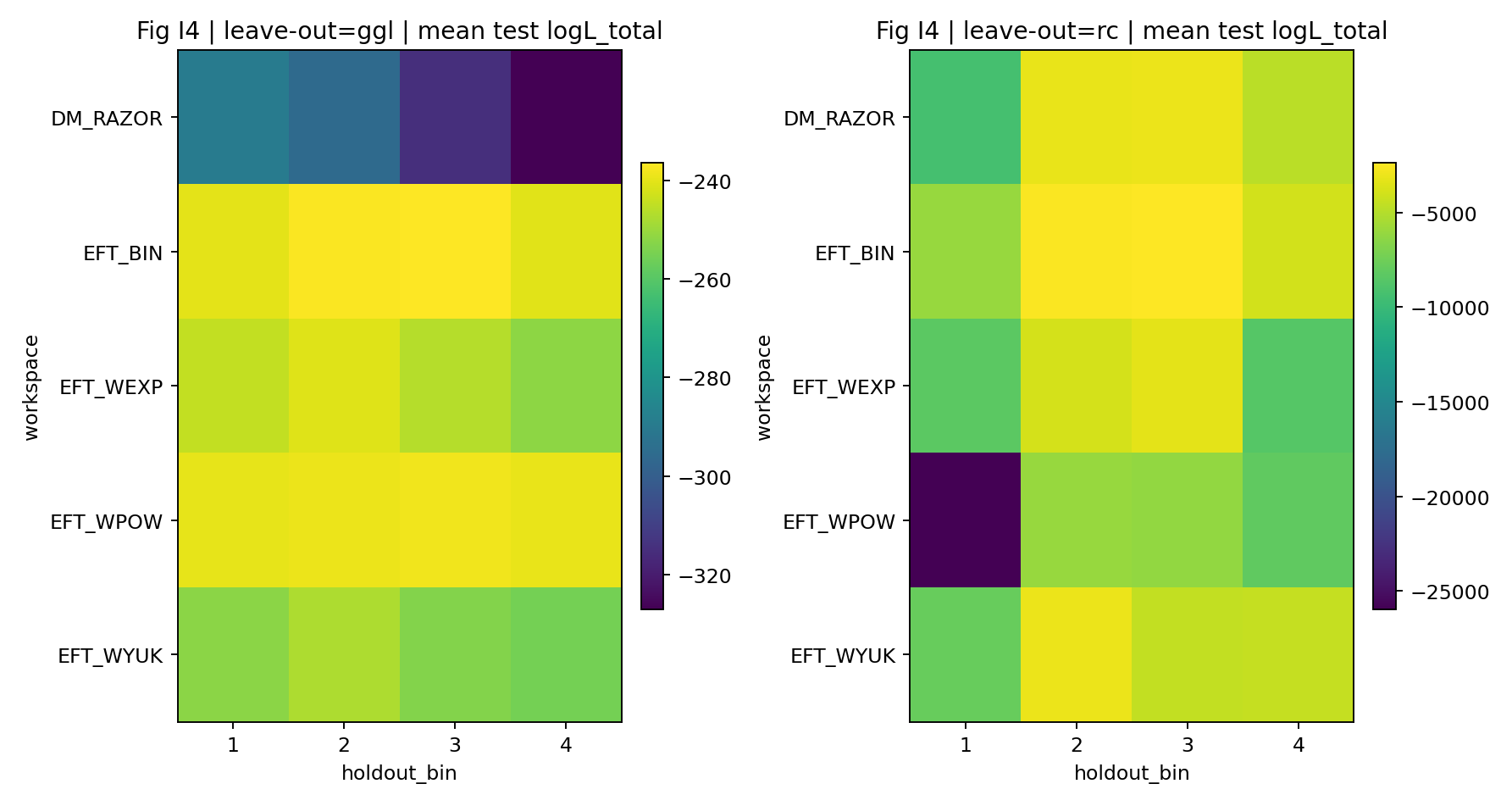
Fig. R6 | LOO: distribuzione della log-verosimiglianza per il bin trattenuto (da prodotti Run-9).
6.6 Controllo negativo: shuffle dei bin RC (Run-10)
Run-10 raggruppa casualmente i 20 bin RC in 4×5 e ricalcola la chiusura mantenendo invariato il posteriore RC-only. I risultati mostrano che, rispetto alla mappatura originale, lo shuffle abbassa significativamente sia la media di chiusura logL_true sia ΔlogL_closure (si vedano Tabella S1b e Fig. R1), sostenendo ulteriormente l’interpretabilità del segnale di chiusura.
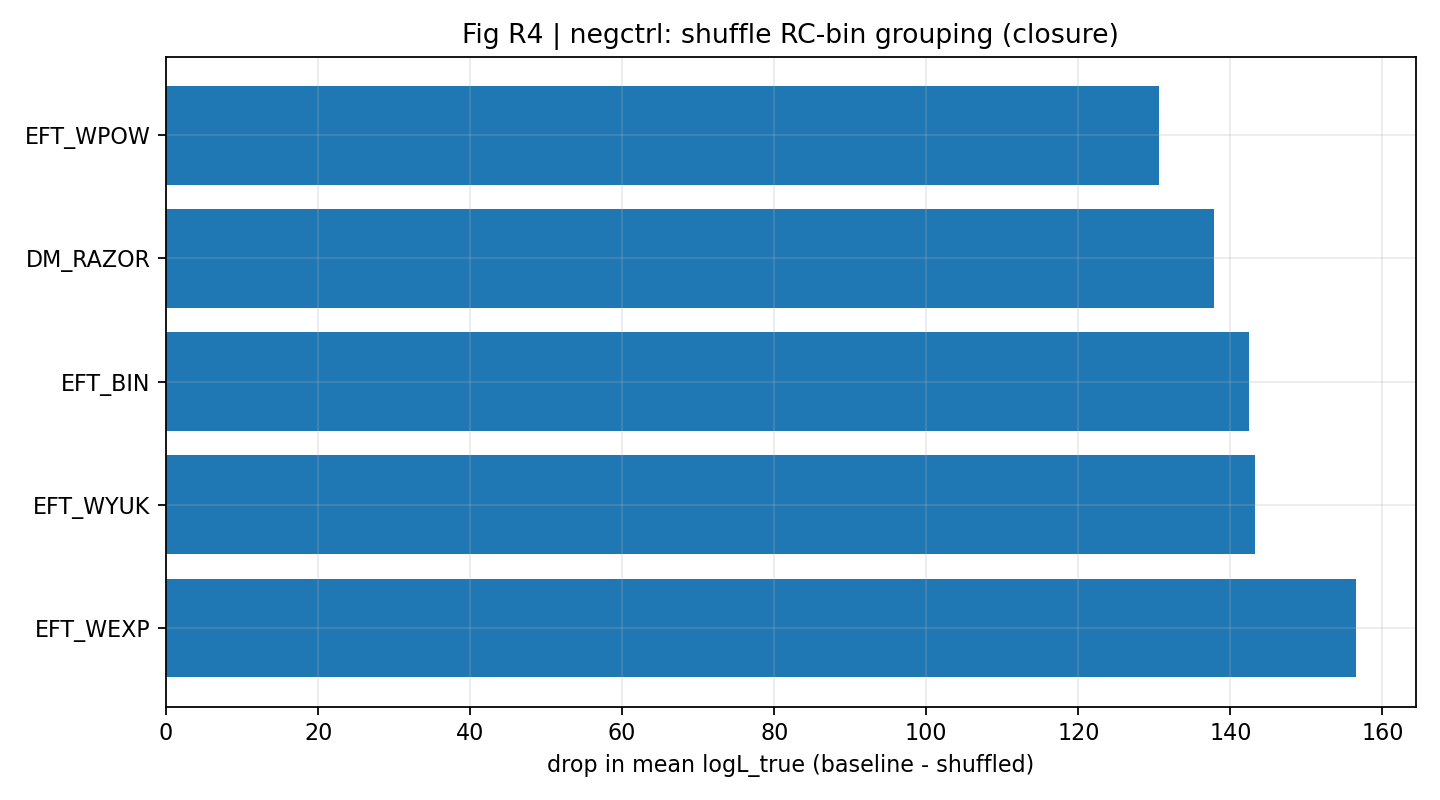
Fig. R7 | Controllo negativo: la mappatura shuffle causa un chiaro calo della media di chiusura logL_true (da prodotti Run-10).
7 Tracciabilità e audit di coerenza (provenance)
Tutti i valori numerici citati in questo articolo possono essere tracciati voce per voce nelle tabelle di sintesi rigorose e nei record di audit dell’archivio di release. Per mantenere più leggibile il testo principale, l’intera catena di provenance (lista dei tag, tabelle di audit, lista dei checksum e metodo di verifica) è stata spostata nell’Appendice A.
8 Riproducibilità e archivio Zenodo
Dichiarazione di disponibilità di dati e codice: i dati delle curve di rotazione SPARC e i dati di lensing debole KiDS-1000 usati in questo articolo sono dataset pubblici. Il rapporto di livello pubblicabile è stato archiviato su Zenodo (Concept DOI: https://doi.org/10.5281/zenodo.18526334), e il pacchetto completo di riproduzione è stato archiviato su Zenodo (Concept DOI: https://doi.org/10.5281/zenodo.18526286). Passi di esecuzione dettagliati, ambiente delle dipendenze, inventario d’archivio e informazioni di verifica hash sono forniti nell’Appendice A; il disegno, i run tag e gli output dello stress test di standardizzazione della baseline DM (P1A) sono forniti nell’Appendice B.
Sotto lo stesso Concept DOI del pacchetto completo di riproduzione (https://doi.org/10.5281/zenodo.18526286), forniamo due punti di ingresso riproducibili in base al caso d’uso: • P1 (testo principale) full_fit_runpack: riproduce le analisi RC-only / closure / joint e le scansioni di robustezza per EFT vs DM_RAZOR, e genera gli asset del testo principale, incluse Tabelle S1a/S1b e Figg. S3/S4; • P1A (Appendice B) full_fit_runpack: riproduce lo stress test di standardizzazione della baseline DM (SCAT/AC/FB + prior gerarchico sulla dispersione c–M + core1p + lensing m + DM_STD, incluso il controllo EFT_BIN), e genera la Tabella B1 e la Fig. B1 dell’appendice. Le tabelle/figure supplementari e il full_fit_runpack di P1A saranno inclusi come file aggiuntivi sotto lo stesso Concept DOI, per mantenere un unico punto di ingresso d’archivio.
9 Ringraziamenti e dichiarazioni
9.1 Ringraziamenti
Ringraziamo i team SPARC e KiDS-1000 per aver fornito dati e documentazione pubblici, e i partecipanti al workflow di ricostruzione e audit di questo progetto.
9.2 Contributi dell’autore
Guanglin Tu è stato responsabile della proposta concettuale, del disegno dello studio, dell’implementazione ingegneristica, della curatela dei dati, dell’analisi formale, dell’implementazione e audit del workflow di riproducibilità, e della scrittura del manoscritto.
9.3 Finanziamento
Autofinanziato dall’autore, Guanglin Tu (nessun finanziamento esterno / nessun numero di grant).
9.4 Interessi concorrenti
L’autore, Guanglin Tu, è affiliato all’“EFT Working Group, Shenzhen Energy Filament Science Research Co., Ltd. (Cina)”; non sono dichiarati altri interessi concorrenti.
9.5 Assistenza IA
OpenAI GPT-5.2 Pro e Gemini 3 Pro sono stati usati per rifinitura linguistica, editing strutturale e organizzazione del workflow di riproducibilità. Non sono stati usati per generare o modificare dati, risultati, figure, tabelle o codice, né per generare citazioni. L’autore si assume piena responsabilità per il contenuto e l’accuratezza delle citazioni dell’intero manoscritto.
10 Riferimenti
- Lelli, F., McGaugh, S. S., & Schombert, J. M. (2016). SPARC: Mass Models for 175 Disk Galaxies with Spitzer Photometry and Accurate Rotation Curves. The Astronomical Journal, 152, 157. DOI: 10.3847/0004-6256/152/6/157.
- Brouwer, M. M., Oman, K. A., Valentijn, E. A., et al. (2021). The weak lensing radial acceleration relation: Constraining modified gravity and cold dark matter theories with KiDS-1000. Astronomy & Astrophysics, 650, A113. DOI: 10.1051/0004-6361/202040108.
- Wright, C. O., & Brainerd, T. G. (2000). Gravitational Lensing by Navarro–Frenk–White Halos. The Astrophysical Journal, 534, 34–40.
- Navarro, J. F., Frenk, C. S., & White, S. D. M. (1997). A Universal Density Profile from Hierarchical Clustering. Astrophysical Journal, 490, 493. DOI: https://doi.org/10.1086/304888
- Dutton, A. A., & Macciò, A. V. (2014). Cold dark matter haloes in the Planck era: evolution of structural parameters for NFW haloes. Monthly Notices of the Royal Astronomical Society, 441, 3359–3374. DOI: https://doi.org/10.1093/mnras/stu742
- Blumenthal, G. R., Faber, S. M., Flores, R., & Primack, J. R. (1986). Contraction of dark matter galactic halos due to baryonic infall. Astrophysical Journal, 301, 27. DOI: https://doi.org/10.1086/163867
- Di Cintio, A., Brook, C. B., Dutton, A. A., et al. (2014). A mass-dependent density profile for dark matter haloes including the influence of galaxy formation. Monthly Notices of the Royal Astronomical Society, 441, 2986–2995. DOI: https://doi.org/10.1093/mnras/stu729
- Read, J. I., Agertz, O., & Collins, M. L. M. (2016). Dark matter cores all the way down. Monthly Notices of the Royal Astronomical Society, 459, 2573–2590. DOI: https://doi.org/10.1093/mnras/stw713
- Energy Filament Theory. Zenodo (open science repository) DOI: https://doi.org/10.5281/zenodo.18517411
Appendice A: dettagli di tracciabilità e riproducibilità
Questa appendice riassume le informazioni d’archivio a lungo termine per tracciabilità e riproducibilità, inclusi run tag, risultati di audit, inventari d’archivio e punti chiave di verifica, affinché i lettori possano controllare e riprodurre il lavoro secondo necessità.
A.1 Dettagli di tracciabilità e audit
Per garantire tracciabilità a lungo termine, questo progetto usa tag con timestamp per ogni run e output e conserva i prodotti storici senza sovrascriverli. I valori centrali citati in questo manoscritto provengono dalla compilazione rigorosa (compile_tag=20260205_035929) e hanno superato i seguenti audit di coerenza:
• Tutte le tabelle a livello di fase portano run_tag e stage tag; lo script di compilazione rigorosa seleziona fonti tabellari canoniche “complete e coerenti” da report/tables.
• I valori in Tab_Z1_master_summary e Tab_Z2_conclusion_highlights sono confrontati voce per voce con le tabelle canoniche selezionate.
• Durante la generazione del PDF, viene eseguito un audit dei tag sulle “tabelle/figure referenziate” per garantire che prodotti obsoleti non vengano mescolati.
Tag chiave (per localizzare tutti i prodotti intermedi): run_tag=20260204_122515; closure_tag=20260204_124721; joint_tag=20260204_152714; sigma_sweep_tag=20260204_161852; rmin_sweep_tag=20260204_195247; covshrink_tag=20260204_203219; ablation_tag=20260204_214642; LOO_tag=20260204_224827; negctrl_tag=20260204_234528; strict_compile_tag=20260205_035929; release_tag=20260205_112442.
Risultato dell’audit di coerenza: Tab_AUDIT_checks_strict riporta pass=9, fail=0, skip=0 (si veda il pacchetto di release per i dettagli).
A.2 Passi di esecuzione della riproducibilità e inventario d’archivio
Questo studio adotta un sistema di riproducibilità composto da “rapporto di livello pubblicabile + supplemento tabelle/figure + pacchetto di run completamente rieseguibile”. I lettori possono consultare direttamente il Tables & Figures Supplement per verificare tutti gli asset tabellari/figurativi citati nell’articolo; per riprodurre da zero i valori numerici e la catena di audit, possono usare il full_fit_runpack per scaricare i dati e rieseguire l’intero workflow. Al termine, lo script di confronto con tabelle di riferimento integrato nel pacchetto può essere usato per verificare la coerenza dei valori tabellari.
A.2.1 Avvio rapido della riproduzione (RUN_FULL, Windows PowerShell)
Questa sezione fornisce un percorso di riproduzione più breve (Windows PowerShell). Per controlli rapidi, si consiglia ai lettori di consultare direttamente il Tables & Figures Supplement e verificare voce per voce tabelle e figure citate. Per la riproduzione end-to-end e la generazione di tutte le tabelle, figure e prodotti di audit, usare il full_fit_runpack: seguire README/ONE_PAGE_REPRO_CHECKLIST del pacchetto per eseguire verify_checksums.ps1 e RUN_FULL.ps1 (Mode=full consigliato).
Voce dell’archivio Zenodo (Concept DOI): https://doi.org/10.5281/zenodo.18526286.
Tag della catena principale per questo articolo: run_tag=20260204_122515; strict compile_tag=20260205_035929; release_tag=20260205_112442.
A.2.2 Materiali d’archivio e punti chiave di verifica (pacchetti e controlli)
L’archivio Zenodo fornisce tre categorie complementari di materiali: (1) rapporto di livello pubblicabile (questo articolo, v1.1; inclusa l’Appendice B: stress test di standardizzazione della baseline DM P1A); (2) Tables & Figures Supplement (tabelle e figure supplementari che coprono tutti gli asset tabellari/figurativi citati in questo articolo, corrispondenti separatamente a P1 e P1A); e (3) full_fit_runpack (pacchetto completo di riproduzione: scarica i dati da zero e riesegue l’intero workflow, corrispondente separatamente a P1 e P1A). Gli elementi (1)–(2) supportano lettura rapida e verifica indipendente; l’elemento (3) fornisce piena riproducibilità end-to-end.
Categoria di materiale | Nome file (esempio) | Scopo e posizionamento (ordine d’uso consigliato) |
Rapporto di livello pubblicabile (cinese e inglese) | P1_RC_GGL_report_EN_PUBLICATION_V1_1.pdf | Rapporto completo archiviato su Zenodo; il testo principale fornisce le conclusioni centrali e gli audit di robustezza, mentre l’Appendice B fornisce P1A (stress test di standardizzazione della baseline DM). |
Tables & Figures Supplement (P1) | P1_RC_GGL_supplement_figs_tables_V1_1.zip | Tutte le tabelle (CSV) e le figure (PNG) citate nel testo principale, inclusi script di generazione e file tag. |
Tables & Figures Supplement (P1A) | P1A_supplement_figs_tables_v1.zip | Tutte le tabelle e figure citate nell’Appendice B (P1A), incluse Tab_S1_P1A_scoreboard e Fig_S1_P1A_scoreboard. |
full_fit_runpack (P1) | P1_RC_GGL_full_fit_runpack_v1_1.zip | Riproduzione completa end-to-end: scarica i dati da zero e riesegue RC-only/closure/joint e le scansioni di robustezza. |
full_fit_runpack (P1A) | P1A_RC_GGL_full_fit_runpack_v1.zip | Riproduzione completa end-to-end (Appendice B): riesegue DM 7+1 + DM_STD (incluso il controllo EFT_BIN) e genera gli asset dell’appendice; il pacchetto include uno script di confronto con tabelle di riferimento per verificare la coerenza dei valori tabellari. |
Raccomandazione di citazione: quando si cita questo articolo o i materiali di riproducibilità associati, si prega di citare il Zenodo Concept DOI (https://doi.org/10.5281/zenodo.18526334).
I prodotti chiave che dovrebbero comparire ed essere confrontabili dopo la riproduzione includono:
- report/tables/Tab_D_closure_summary__20260204_122515__*.csv (closure summary)
- report/tables/Tab_F_joint_summary__20260204_122515__*.csv (joint-fit summary)
- report/tables/Tab_G_joint_sigma_sweep__20260204_122515__*.csv (σ_int scan)
- report/tables/Tab_H_joint_rmin_sweep__20260204_122515__*.csv (R_min scan)
- report/tables/Tab_I_joint_covshrink_sweep__20260204_122515__*.csv (cov-shrink scan)
- report/tables/Tab_R2_ablation_ladder__20260204_122515__*.csv (ablation)
- report/tables/Tab_R3_leave_one_bin_out__20260204_122515__*.csv (LOO)
- report/tables/Tab_R4_negctrl_rcbin_shuffle__20260204_122515__*.csv (negative control)
- report/final/Tab_Z1_master_summary__20260204_122515__20260205_035929.csv (Strict master table; corresponds to Tables S1a/S1b and main-text values)
- report/final/P1_RC_GGL_final_bundle__20260204_122515__20260205_035929.pdf (publication-grade PDF bundle; can be used for quick browsing and citation)
Appendice B: P1A—stress test di standardizzazione della baseline DM (DM 7+1 + DM_STD; con controllo EFT)
Questa appendice documenta un progetto di estensione (P1A) per lo “stress test di standardizzazione della baseline DM” coerente con il protocollo di chiusura del testo principale. Il suo ruolo è aggiornare la baseline minima DM_RAZOR usata nel testo principale (NFW + c–M fisso, nessuna dispersione / nessuna contrazione / nessun core) in un insieme di baseline DM più vicino alla pratica astrofisica e più resistente alle critiche comuni, senza introdurre un gran numero di gradi di libertà e senza cambiare la mappatura condivisa RC-bin→GGL-bin o il framework di audit. P1A copre, ed è un sovrainsieme del precedente stress test a tre rami: mantiene SCAT/AC/FB aggiungendo dispersione c–M gerarchica + prior, un proxy core a un parametro e una nuisance m di calibrazione shear lato lensing; fornisce inoltre il modello combinato DM_STD. EFT_BIN è mantenuto come riferimento di controllo.
Nota supplementare: le forze di chiusura e i valori correlati nell’Appendice B (P1A) usano un budget Monte Carlo più grande (per esempio, ndraw=400, nperm=24) rispetto al budget rapido usato nel testo principale per coprire l’intera famiglia di kernel EFT (per esempio, ndraw=60, nperm=12). Pertanto, i valori assoluti possono mostrare drift di campionamento di livello O(10). Tuttavia, i confronti modello-modello all’interno dello stesso budget/tabella sono equi, e segno e scala del vantaggio restano stabili tra budget diversi.
B.1 Scopo e posizionamento (perché P1A e perché come appendice)
P1A non tenta di esaurire tutte le possibili scelte di modellizzazione degli aloni ΛCDM (come non sfericità, dipendenza ambientale, connessioni galassia-alone complesse o fisica barionica ad alta dimensionalità). Segue invece un principio “a bassa dimensionalità, verificabile, riproducibile”: ogni modulo di miglioramento introduce solo ≤1 parametro efficace chiave e resta soggetto ai tre vincoli rigidi di questo articolo:
(i) Registro dei parametri: ogni nuovo parametro deve essere esplicitamente registrato e riportato insieme ai criteri informativi (AICc/BIC);
(ii) Mappatura condivisa: si usa ancora la stessa mappa di raggruppamento RC-bin→GGL-bin; non è consentito “tarare la mappatura” separatamente per un singolo dataset;
(iii) Test di chiusura: qualunque miglioramento deve mostrare un guadagno genuino nella previsione trasferibile RC→GGL, non solo un miglior fit RC-only.
B.2 DM 7+1 + DM_STD: definizioni dei moduli, parametri e ingresso nel posteriore congiunto
Come runpack indipendente, P1A fornisce 8 workspace DM (DM 7+1) più 1 controllo EFT: partendo da DM_RAZOR come baseline, costruisce tre miglioramenti legacy a un parametro (DM_RAZOR_SCAT / DM_RAZOR_AC / DM_RAZOR_FB), aggiunge tre moduli difensivi più standard (DM_HIER_CMSCAT / DM_CORE1P / DM_RAZOR_M) e quindi fornisce il modello combinato DM_STD. L’obiettivo condiviso di questi moduli è coprire le tre classi di critica più comuni aumentando la dimensionalità il meno possibile: (a) come dispersione c–M e prior entrano in un modello gerarchico; (b) se l’effetto principale del feedback barionico può essere catturato da un proxy core a un parametro; e (c) se sistematiche chiave lato lensing possano essere scambiate per un segnale fisico.
Workspace | dm_model | Nuovi parametri (≤1) | Motivazione fisica (nucleo) | Principio di implementazione (audit-friendly) |
|---|---|---|---|---|
DM_RAZOR | NFW (c–M fisso, nessuna dispersione) | — | Baseline di alone ΛCDM minima e verificabile; usata per confronto rigoroso con EFT | Mappatura condivisa fissa; registro dei parametri rigoroso; usata solo come baseline per confronto relativo |
DM_RAZOR_SCAT | NFW + dispersione c–M (legacy) | σ_logc | La relazione c–M presenta dispersione; approssimata con dispersione log-normale a un parametro | ≤1 nuovo parametro; mappatura condivisa mantenuta; guadagno di chiusura usato come criterio di accettazione |
DM_RAZOR_AC | NFW + contrazione adiabatica (legacy) | α_AC | L’infall barionico può indurre contrazione adiabatica dell’alone; approssimata con una forza a un parametro | ≤1 nuovo parametro; mappatura invariata; si riportano variazioni AICc/BIC e guadagno di chiusura |
DM_RAZOR_FB | NFW + core da feedback (legacy) | log r_core | Il feedback può formare un core nella regione interna; approssimato con una scala core a un parametro | ≤1 nuovo parametro; stesso protocollo di chiusura/controllo negativo; il miglioramento RC-only non è l’unico obiettivo |
DM_HIER_CMSCAT | Dispersione c–M gerarchica + prior | σ_logc (gerarchico) | Più standard: c_i∼logN(c(M_i),σ_logc) gerarchico; influenza il posteriore congiunto di RC e GGL | Prior esplicito; c_i latenti marginalizzati; resta a bassa dimensionalità e verificabile |
DM_CORE1P | Proxy core a 1 parametro (ispirato a coreNFW/DC14) | log r_core | Usa un proxy core a un parametro per l’effetto principale del feedback barionico, evitando dettagli di formazione stellare ad alta dimensionalità | Cita letteratura standard; ≤1 nuovo parametro; vincolato al test di chiusura |
DM_RAZOR_M | NFW + nuisance di calibrazione shear del lensing | m_shear (GGL) | Assorbe una sistematica chiave del lensing debole come parametro efficace, riducendo il rischio di scambiare sistematiche per fisica | Nuisance registrata esplicitamente; non può retroagire su RC; risultati giudicati soprattutto dalla robustezza della chiusura |
DM_STD | Baseline DM standardizzata (HIER_CMSCAT + CORE1P + m) | σ_logc + log r_core (+ m_shear) | Include le tre classi di critica più comuni in una baseline standard ancora a bassa dimensionalità | Registro dei parametri + criteri informativi riportati; la chiusura è la metrica primaria; usata come controllo difensivo DM più forte |
Nota: i nomi dei parametri sopra seguono l’implementazione ingegneristica (per esempio, σ_logc, α_AC, log r_core e m_shear). Il focus progettuale di P1A è “rendere la baseline DM un po’ più forte mantenendola verificabile”, non trasformare il lato DM in un fitter ad alta dimensionalità incontrollabile. In particolare, DM_HIER_CMSCAT introduce la dispersione c–M in modo gerarchico: al parametro di concentrazione c_i di ciascun alone viene assegnata una dispersione log-normale attorno a c(M_i), vincolata dal σ_logc globale e dal prior c(M); questa struttura gerarchica influenza il posteriore congiunto sia di RC sia di GGL.
B.3 Protocollo statistico e convenzioni dei prodotti coerenti con il testo principale
P1A riutilizza tutti i prodotti dati, la mappatura condivisa e il framework di audit del testo principale. L’ordine di esecuzione e le convenzioni dei prodotti restano coerenti:
(1) Run‑1: inferenza RC-only (produce posterior_samples.npz e metrics.json);
(2) Run‑2: test di chiusura RC→GGL (produce closure_summary.json e la baseline permutata);
(3) Run‑3: fit congiunto RC+GGL (produce joint_summary.json).
Tutti i numeri citati provengono dalla tabella compilata automaticamente (Tab_S1_P1A_scoreboard) e possono essere controllati dopo aver rieseguito l’intero workflow P1A usando lo script di confronto con tabella di riferimento integrato nel P1A full_fit_runpack.
B.4 Risultati principali, punti di ingresso tabella/figura e piano d’archivio (stesso DOI)
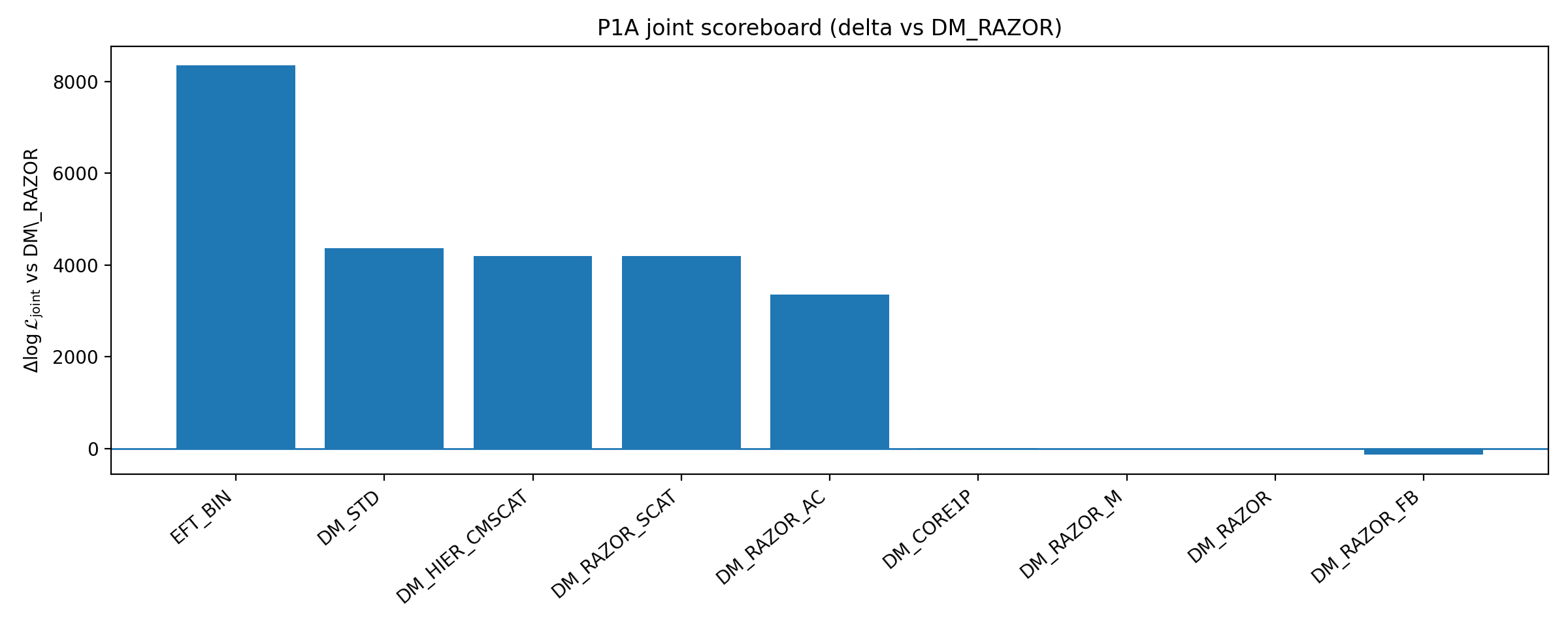
Questa sezione fornisce le conclusioni quantitative centrali di P1A. La Tabella B1 riassume le metriche chiave per RC-only, chiusura RC→GGL e fitting congiunto RC+GGL (le parentesi indicano differenze rispetto alla baseline DM_RAZOR). La forza di chiusura è definita come ΔlogL_closure ≡ ⟨logL_true⟩ − ⟨logL_perm⟩ (più alto è meglio). La Fig. B1 visualizza lo stesso scoreboard. I punti principali sono i seguenti:
• Tra i tre rami legacy, solo DM_RAZOR_FB (feedback/core) produce un piccolo miglioramento netto della forza di chiusura: 122.21→129.45 (+7.25); SCAT e AC non forniscono alcun miglioramento netto;
• I modelli appena aggiunti DM_HIER_CMSCAT e DM_RAZOR_M hanno effetti molto piccoli (~0) sulla forza di chiusura, e anche DM_CORE1P non mostra alcun miglioramento netto significativo;
• Il modello combinato DM_STD può migliorare sostanzialmente logL congiunto (avvicinandosi all’ottimo del fit congiunto), ma la sua forza di chiusura diminuisce, suggerendo che il guadagno derivi principalmente da flessibilità del fit congiunto e non dalla trasferibilità tra sonde;
• Come controllo, EFT_BIN mantiene ancora un chiaro vantaggio sia nella forza di chiusura sia nel fitting congiunto. Pertanto, la conclusione principale è robusta all’introduzione di una “baseline DM più forte + nuisance di lensing”.
Per il confronto diretto con i risultati del testo principale, le Tabelle S1a–S1b riassumono il confronto rigoroso tra la famiglia EFT e DM_RAZOR: i modelli EFT migliorano il fit congiunto di ΔlogL_total≈1155–1337 rispetto a DM_RAZOR e raggiungono ΔlogL_closure=172–281 nel test di chiusura. P1A crea soltanto un “controllo più duro” sul lato DM; il suo scopo è ridurre preoccupazioni come “baseline fantoccio” o “sistematiche-come-fisica”, non sostituire il confronto principale.
Tabella B1 | Scoreboard P1A (più alto è meglio; le parentesi indicano differenze rispetto alla baseline DM_RAZOR).
Ramo del modello (workspace) | Δk | Miglior logL_RC RC-only (Δ) | Forza di chiusura ΔlogL_closure (Δ) | Miglior logL_total congiunto (Δ) |
DM_RAZOR | 0 | -15702.654 (+0.000) | 122.205 (+0.000) | -27347.068 (+0.000) |
DM_RAZOR_SCAT | 1 | -15702.294 (+0.361) | 121.236 (-0.969) | -23153.311 (+4193.758) |
DM_RAZOR_AC | 1 | -15703.689 (-1.035) | 121.531 (-0.674) | -23982.557 (+3364.511) |
DM_RAZOR_FB | 1 | -15496.046 (+206.609) | 129.454 (+7.249) | -27478.531 (-131.463) |
DM_HIER_CMSCAT | 1 | -15702.644 (+0.010) | 121.978 (-0.227) | -23153.160 (+4193.908) |
DM_CORE1P | 1 | -15723.158 (-20.504) | 122.056 (-0.149) | -27336.258 (+10.810) |
DM_RAZOR_M | 0 (+m) | -15702.654 (+0.000) | 122.205 (+0.000) | -27340.451 (+6.617) |
DM_STD | 2 (+m) | -15832.203 (-129.549) | 105.690 (-16.515) | -22984.445 (+4362.623) |
EFT_BIN | 1 | -14631.537 (+1071.117) | 204.620 (+82.415) | -19001.142 (+8345.926) |
Fig. B1 | Scoreboard P1A: chiusura e ΔlogL congiunto rispetto alla baseline (più alto è meglio).
I tag di esempio per il set di run completato corrispondente a questa appendice sono i seguenti (usati per localizzare prodotti intermedi e tabelle/figure di P1A):
P1A run_tag = 20260213_151233; P1A closure_tag = 20260213_161731; P1A joint_tag = 20260213_195428.
B.5 Citazione suggerita (nota sulla citazione dell’appendice)
Quando i lettori devono citare lo “stress test di standardizzazione della baseline DM” in aggiunta alle conclusioni principali dell’articolo, si raccomanda di citare la conclusione principale insieme alla seguente nota: “Si veda l’Appendice B (P1A) per stress test standardizzati della baseline DM (legacy SCAT/AC/FB + prior gerarchico sulla dispersione c–M + proxy core + nuisance di calibrazione shear del lensing), sotto lo stesso protocollo di chiusura.”