Rapporto P1 spiegato
Dalle curve di rotazione al lensing debole: verifica della risposta gravitazionale media di EFT
Consulta il rapporto di valutazione originale:
1. ChatGPT: https://chatgpt.com/share/6a00cd62-6e34-83eb-b165-6ec09e3519cc
2. Gemini: https://gemini.google.com/share/773ec96d75a0
3. Grok: https://grok.com/share/bGVnYWN5LWNvcHk_c0b4fa65-0e86-4adb-9b58-5617d616dc04
4. Qwen: https://chat.qwen.ai/s/22ab9336-671f-420a-a7fa-43e24774bb2a?fev=0.2.46
5. DeepSeek: https://chat.deepseek.com/share/tj6k7hb5owtoldg2bm
Nota di lettura |
Questa è una versione esplicativa, non un rapporto accademico separato. Si basa sul rapporto P1 originale, conserva le figure e le tabelle chiave e aggiunge spiegazioni in linguaggio ordinario di ciò che significa ogni passaggio principale. |
Questa guida spiega solo ciò che P1 conclude entro i dataset, il registro dei parametri e il protocollo statistico specificati: nel test congiunto delle curve di rotazione galattiche (RC) e del lensing debole galassia-galassia (GGL), il modello di risposta gravitazionale media di EFT supera chiaramente la baseline minima DM_RAZOR testata qui. |
Questa guida non interpreta P1 come una tesi secondo cui "la materia oscura è stata rovesciata". P1 è solo il primo passo negli esperimenti della serie P. Testa uno strato osservabile di EFT — la "base gravitazionale media" — non il contenuto completo dell'intero quadro EFT. |
0 | Capire P1 in cinque minuti: che cosa verifica questo test?
Si può pensare a P1 come a un test di coerenza tra sonde diverse. Non si limita a chiedere se un modello riesca ad adattarsi a un singolo insieme di dati. Mette invece sullo stesso banco di verifica due letture gravitazionali molto diverse: le curve di rotazione (RC) leggono la dinamica dentro i dischi galattici, mentre il lensing debole galassia-galassia (GGL) legge la risposta gravitazionale proiettata su scale più grandi.
- RC è come un tachimetro: ci dice a quale velocità gas e stelle ruotano a raggi diversi nel disco di una galassia.
- GGL è come una bilancia: misurando quanto le galassie in primo piano curvano leggermente la luce delle galassie di sfondo, ricava la distribuzione media di gravità/massa attorno alle galassie su scale più ampie.
- La domanda centrale di P1 è questa: lo stesso modello può prima apprendere uno schema da RC, poi trasferirlo a GGL e continuare ad avere senso?
P1 in una frase |
P1 alza l'asticella da "si adatta bene a una sonda?" a "chiude tra sonde?" Un modello ha più probabilità di aver catturato una struttura gravitazionale condivisa da RC e GGL solo se funziona bene sotto la mappatura corretta e il segnale collassa dopo che la mappatura viene mescolata. |
Tabella 0 | I numeri chiave di P1 e come leggerli
Metrica | Lettura in P1 / P1A | Significato in linguaggio ordinario |
ΔlogL_total del fit congiunto | Nel confronto del testo principale, EFT è 1155–1337 sopra DM_RAZOR | La differenza di punteggio totale sui due dataset; più grande significa una spiegazione complessiva migliore. |
Forza di chiusura ΔlogL_closure | Nel confronto del testo principale, EFT è 172–281, mentre DM_RAZOR è 127 | La capacità di prevedere GGL dopo l'inferenza da RC soltanto; più grande significa maggiore auto-coerenza tra sonde. |
Shuffle di controllo negativo | Dopo aver mescolato RC-bin→GGL-bin, il segnale di chiusura EFT scende a 6–23 | Se la corrispondenza corretta viene spezzata, il vantaggio dovrebbe scomparire; quanto più netto è il collasso, tanto meglio esclude un segnale spurio. |
Stress test multi-DM P1A | DM 7+1 + DM_STD, con EFT_BIN mantenuto come confronto | P1A non guarda soltanto alla baseline minima DM_RAZOR. Inserisce più rami di potenziamento DM a bassa dimensionalità e verificabili nello stesso protocollo di chiusura. |
1 | Perché svolgere P1? Dove si blocca la cosmologia su scala galattica?
I problemi su scala galattica sono rimasti difficili perché il "fabbisogno di gravità/massa extra" non è soltanto un fenomeno delle curve di rotazione. Molte osservazioni mostrano un legame stretto tra la materia barionica visibile nelle galassie e le letture dinamiche o di lensing effettive. Per la via della materia oscura, questo significa che aloni oscuri, feedback barionico, storia di formazione delle galassie e sistematiche osservative devono essere coordinati con grande precisione. Per le vie gravitazionali senza materia oscura, significa che un modello non può limitarsi a funzionare bene su RC: deve reggere anche il lensing debole, le relazioni di scala delle popolazioni e i controlli negativi.
Questa è la motivazione di P1. Il lavoro non parte da "la materia oscura è sbagliata" né da "EFT deve essere giusta". Porta in verifica una tesi testabile: la risposta gravitazionale media di EFT può lasciare un segnale riproducibile e trasferibile nella chiusura tra sonde RC→GGL?
Contesto della letteratura esterna: perché la finestra RC+GGL è importante |
La relazione di accelerazione radiale (RAR) proposta da McGaugh, Lelli e Schombert nel 2016 mostra una correlazione stretta e a bassa dispersione tra l'accelerazione osservata tracciata dalle curve di rotazione e l'accelerazione prevista dalla materia barionica. Questo rende inevitabile l'accoppiamento "barioni–risposta gravitazionale" per la teoria su scala galattica. |
Brouwer et al. (2021) hanno usato il lensing debole KiDS-1000 per estendere la RAR ad accelerazioni più basse e raggi più grandi, confrontando MOND, la gravità emergente di Verlinde e modelli LambdaCDM. Hanno anche osservato che le differenze tra galassie di tipo precoce e tardivo, gli aloni di gas e il collegamento galassia–alone restano questioni esplicative centrali. |
Mistele et al. (2024) hanno inoltre usato il lensing debole per inferire curve di velocità circolare per galassie isolate, riportando assenza di chiaro calo fino a diverse centinaia di kpc e persino fino a circa 1 Mpc, in accordo con la BTFR. Questo mostra che il lensing debole sta diventando una lettura esterna importante per testare la risposta gravitazionale su scala galattica. |
Il valore di P1, quindi, non sta nell'essere il "primo a discutere insieme RC e GGL". Sta nel collocarli dentro un protocollo verificabile, costruito su una mappatura fissa, un registro dei parametri, una chiusura RC-only→GGL, controlli negativi con shuffle e stress test multi-DM P1A.
2 | Che cosa significa EFT in P1? Non è Effective Field Theory
Qui EFT indica la Teoria del filamento di energia (Energy Filament Theory, EFT), non la Effective Field Theory comunemente usata in fisica. Nel rapporto tecnico P1, EFT viene impiegata con prudenza: non entra nel confronto come teoria finale completa, ma viene prima compressa in una parametrizzazione osservabile, pronta per il fitting e falsificabile della "risposta gravitazionale media".
In parole semplici, P1 non inizia discutendo ogni sorgente microscopica di gravità extra e non tenta di dimostrare l'intero quadro EFT in un colpo solo. Pone una domanda più stretta e più dura: se su scala galattica esiste una qualche risposta gravitazionale extra media, può prima spiegare RC e poi trasferirsi per prevedere GGL?
Quale parte di EFT testa P1? |
P1 mira alla "base gravitazionale media": un contributo medio statisticamente stabile, trasferibile tra campioni. |
P1 non tratta ancora la "base stocastica/di rumore": i termini casuali, le differenze individuali o la dispersione aggiuntiva che processi di fluttuazione più microscopici potrebbero introdurre. |
P1 non affronta nemmeno il meccanismo microscopico completo, l'abbondanza, la vita media o i vincoli cosmologici globali. È il primo passo degli esperimenti della serie P, non un verdetto finale. |
3 | Il piano della serie P1: perché iniziare dalla "base media"?
La serie P può essere intesa come il programma di recupero osservativo di EFT. Non espone tutte le tesi in una volta; isola invece la parte più facilmente verificabile con dati pubblici. La strategia di P1 è testare prima il termine medio: se la risposta gravitazionale media non riesce nemmeno a chiudere da RC a GGL, allora discutere termini di rumore più complessi o meccanismi microscopici non ha un vero punto d'ingresso.
Tabella 1 | Collocazione a livelli della serie P
Livello | Domanda posta | Ruolo in P1 |
P1 | La risposta gravitazionale media può chiudere in RC→GGL? | Domanda principale del presente rapporto |
P1A | Se il lato DM viene rafforzato, la conclusione resta stabile? | Appendice B: stress test DM 7+1 + DM_STD |
Lavori successivi della serie P | Il protocollo può essere esteso a più dati, più sonde e sistematiche più complesse? | Direzione per lavori futuri |
Domande di livello più profondo | Come si collegano il termine medio, il termine di rumore e il meccanismo microscopico? | Fuori dall'ambito delle conclusioni di P1 |
4 | Quali sono i dati? Che cosa ci dicono RC e GGL?
4.1 Curve di rotazione (RC): il "misuratore di velocità" dentro i dischi galattici
Le curve di rotazione registrano quanto velocemente gas e stelle orbitano attorno al centro di una galassia a raggi diversi. Quanto più rapida è la rotazione, tanto maggiore è la forza centripeta richiesta a quel raggio — e quindi tanto più forte è la gravità effettiva. P1 usa il database SPARC, con una pre-elaborazione che include 104 galassie e 2.295 punti di velocità, suddivisi in 20 RC-bin.
4.2 Lensing debole (GGL): una "bilancia gravitazionale" su scala più ampia
Il lensing debole galassia-galassia misura come le galassie in primo piano curvino leggermente la luce delle galassie di sfondo. Corrisponde a una risposta gravitazionale proiettata su raggi più grandi, di scala d'alone, e non dipende dai dettagli della dinamica del gas all'interno della galassia. P1 usa i dati pubblici GGL di KiDS-1000 / Brouwer et al. (2021): 4 bin di massa stellare, 15 punti radiali per bin, 60 punti dati in totale, usando la covarianza completa.
4.3 Mappatura fissa: perché 20 RC-bin → 4 GGL-bin è importante
P1 collega i 20 RC-bin ai 4 GGL-bin tramite una regola fissa: ogni GGL-bin corrisponde a 5 RC-bin, combinati con una media pesata per il numero di galassie. Questa mappatura resta invariata per tutti i modelli e agisce come vincolo rigido per il test di chiusura e il confronto equo.
Perché non tarare la mappatura a posteriori? |
Se si potesse scegliere a posteriori "quali RC-bin corrispondono a quali GGL-bin", un modello potrebbe fabbricare la chiusura riordinando la corrispondenza. P1 blocca in anticipo la mappatura 20→4 e la rompe deliberatamente con un controllo negativo shuffle proprio per giudicare se il segnale di chiusura dipenda davvero da una corrispondenza fisicamente ragionevole. |
5 | Modelli e metodi: che cosa confronta esattamente P1?
5.1 Il lato EFT: risposta gravitazionale media a bassa dimensionalità
Sul lato EFT, un termine di velocità extra a bassa dimensionalità viene usato per descrivere la risposta gravitazionale media. La forma del termine extra è controllata da una funzione kernel adimensionale f(r/ℓ), dove ℓ è la scala globale, e l'ampiezza è assegnata per RC-bin. Kernel diversi rappresentano pendenze iniziali, velocità di transizione e code a lungo raggio diverse, e sono usati per stress test di robustezza.
5.2 Il lato DM: il confronto del testo principale e l'Appendice P1A vanno letti separatamente
Nel confronto del testo principale, DM_RAZOR è una baseline NFW minimizzata e verificabile: usa una relazione c–M fissa e non include dispersione da alone ad alone, contrazione adiabatica, core da feedback, non sfericità o termini ambientali. Il punto di forza di questo disegno è il controllo dei gradi di libertà e la facile riproducibilità; il suo limite è che non può rappresentare ogni modello LambdaCDM o ogni modello di alone di materia oscura.
Perciò, nell'Appendice B (P1A), il lato DM viene trasformato in una serie di "stress test standardizzati". Senza cambiare la mappatura condivisa o il protocollo di chiusura, P1A aggiunge gradualmente rami di potenziamento a bassa dimensionalità come SCAT, AC, FB, HIER_CMSCAT, CORE1P, lensing m e la baseline combinata DM_STD, mantenendo EFT_BIN come confronto. In breve, P1A non è un confronto con una sola baseline DM minima; misura un insieme di meccanismi DM comuni e verificabili con lo stesso "righello di chiusura".
La formulazione precisa della conclusione usata qui |
Testo principale: la famiglia EFT supera nettamente il minimo DM_RAZOR nel confronto principale. |
Appendice B / P1A: con più rami di potenziamento DM a bassa dimensionalità e verificabili e con lo stress test DM_STD, alcuni fit congiunti DM migliorano, ma la forza di chiusura non elimina il vantaggio di EFT_BIN. |
La formulazione più sicura è quindi: entro i dati, la mappatura, il registro dei parametri e il protocollo di chiusura di P1/P1A, la risposta gravitazionale media di EFT mostra una coerenza tra dati più forte; ciò non equivale a escludere tutti i modelli di materia oscura. |
5.3 Test di chiusura: la sintassi sperimentale più importante di P1
1. Eseguire il fit usando solo RC per ottenere un insieme di campioni posteriori RC-only.
2. Non ritarare con GGL; usare direttamente il posteriore RC per prevedere GGL.
3. Usare la covarianza completa per calcolare il punteggio di previsione GGL sotto la mappatura corretta, logL_true.
4. Permutare casualmente la corrispondenza RC-bin→GGL-bin per calcolare il punteggio di controllo negativo, logL_perm.
5. Sottrarre i due valori per ottenere la forza di chiusura: ΔlogL_closure = <logL_true> − <logL_perm>.
Analogia in linguaggio ordinario |
Un test di chiusura è come una nuova prova in un'altra aula d'esame. Il modello apprende prima schemi nell'aula RC, poi risponde nell'aula GGL. Se ha appreso una regola condivisa invece di un trucco locale, dovrebbe continuare a rispondere bene dopo il cambio d'aula; se la corrispondenza tra le aule viene deliberatamente mescolata, il vantaggio dovrebbe scomparire. |
5.4 Prima di leggere le tabelle tecniche: quattro punti d'ingresso
Tabella 5.4 | Percorso di lettura per il prossimo gruppo di tabelle tecniche in orizzontale
Punto d'ingresso | Che cosa guardare | Perché è importante |
Tabella S1a | Punteggio totale del fit congiunto RC+GGL | Risponde: "Quando i due dataset sono considerati insieme, quale spiegazione complessiva è più forte?" |
Tabella S1b | Forza di chiusura, shuffle e scan di robustezza | Risponde: "Ciò che è stato appreso da RC può trasferirsi a GGL?" |
Tabella B0 | Definizioni di più rami di potenziamento DM in P1A | Impedisce di ridurre P1 a "solo un confronto con il minimo DM_RAZOR". |
Tabella B1 | Scoreboard P1A di chiusura e fit congiunto | Verifica se il vantaggio di chiusura scompare dopo il rafforzamento della DM. |
Nota di layout |
Le pagine in orizzontale iniziano dalla pagina successiva in modo da conservare integralmente le tabelle larghe del rapporto originale, senza eliminare colonne o comprimerle fino a renderle illeggibili. Il testo principale ha già fornito una lettura in linguaggio ordinario; le tabelle tecniche in orizzontale sono per i lettori che devono verificare valori e rami di modello. |
Figura 0.1 | Il flusso di lavoro del test di chiusura di P1 in un diagramma
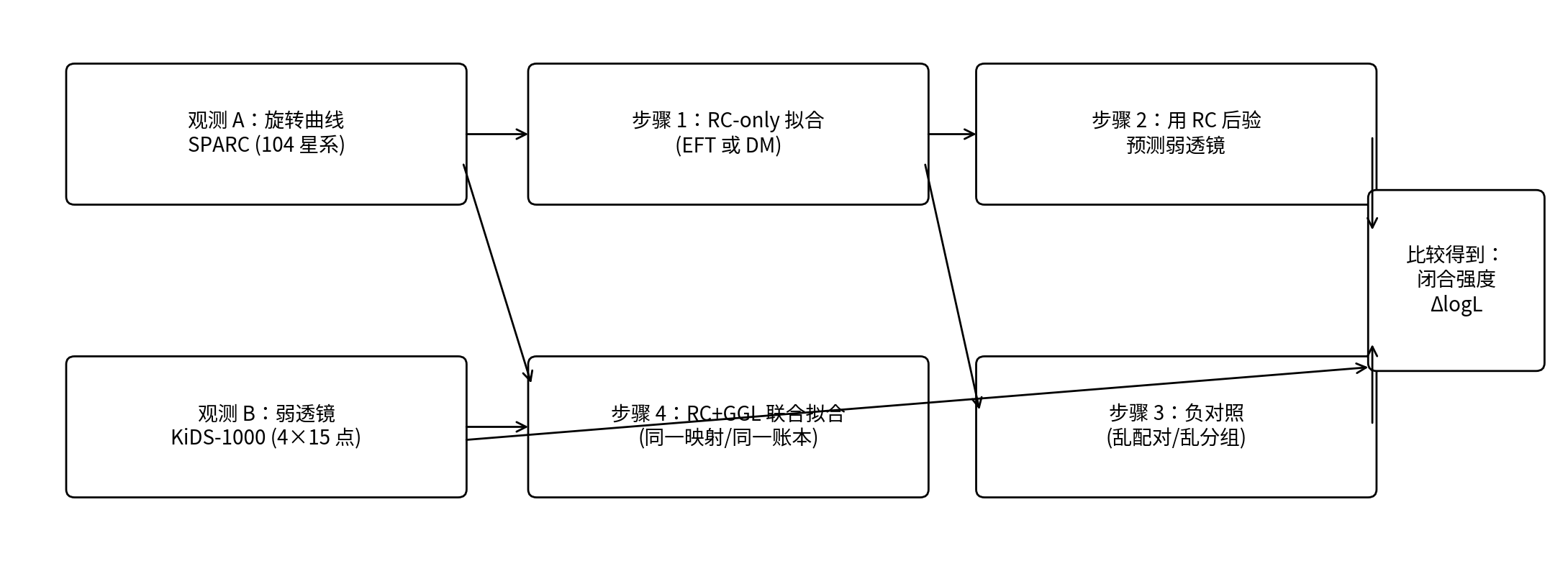
Nota: la catena superiore è il "test di chiusura" (fit solo su RC → uso del posteriore RC per prevedere GGL); la catena inferiore è il "fit congiunto" (valutazione congiunta RC+GGL). A destra, la mappatura reale viene confrontata con la mappatura mescolata per ottenere la forza di chiusura ΔlogL.
6 | Tabelle tecniche chiave: tabelle principali del rapporto originale e tabelle P1A
Tabella S1a | Metriche principali del confronto di fit congiunto (RC+GGL, rigorose; mantenuta dal rapporto originale)
Modello (workspace) | Kernel W | k | logL_total congiunto (migliore) | ΔlogL_total rispetto a DM | AICc | BIC |
DM_RAZOR | nessuno | 20 | -16927.763 | 0.0 | 33895.885 | 34010.811 |
EFT_BIN | nessuno | 21 | -15590.552 | 1337.21 | 31223.501 | 31344.155 |
EFT_WEXP | esponenziale | 21 | -15668.83 | 1258.932 | 31380.057 | 31500.711 |
EFT_WYUK | Yukawa | 21 | -15772.936 | 1154.827 | 31588.268 | 31708.922 |
EFT_WPOW | powerlaw_tail | 21 | -15633.321 | 1294.442 | 31309.038 | 31429.692 |
Tabella S1b | Metriche di chiusura e robustezza (rigorose; mantenute dal rapporto originale)
Modello (workspace) | Closure ΔlogL (true-perm) | ΔlogL dopo shuffle di controllo negativo | Intervallo ΔlogL nello scan σ_int | Intervallo ΔlogL nello scan R_min | Intervallo ΔlogL nello scan cov-shrink |
DM_RAZOR | 126.678 | 22.725 | — | — | — |
EFT_BIN | 231.611 | 14.984 | 459–1548 | 1243–1289 | 1337–1351 |
EFT_WEXP | 171.977 | 6.04 | 408–1471 | 1169–1207 | 1259–1277 |
EFT_WYUK | 179.808 | 14.688 | 380–1341 | 1065–1099 | 1155–1166 |
EFT_WPOW | 280.513 | 6.672 | 457–1500 | 1203–1247 | 1294–1308 |
Tabella B0 | Definizioni dei rami di potenziamento DM in P1A (mantenuta dall'Appendice B del rapporto originale)
Workspace | dm_model | Nuovo parametro (≤1) | Motivazione fisica (nucleo) | Principio di implementazione (audit-friendly) |
|---|---|---|---|---|
DM_RAZOR | NFW (c–M fisso, nessuna dispersione) | — | Baseline di alone LambdaCDM minima e verificabile; usata come confronto rigoroso con EFT | Mappatura condivisa fissa; registro dei parametri rigoroso; usata solo come baseline di confronto relativo |
DM_RAZOR_SCAT | NFW + dispersione c–M (legacy) | σ_logc | La relazione c–M presenta dispersione; approssimata con una dispersione lognormale a un parametro | ≤1 nuovo parametro; usa ancora la mappatura condivisa; il guadagno di chiusura è il criterio di accettazione |
DM_RAZOR_AC | NFW + contrazione adiabatica (legacy) | α_AC | L'infall barionico può causare contrazione adiabatica dell'alone; approssimata con una forza a un parametro | ≤1 nuovo parametro; mappatura invariata; riporta cambiamenti AICc/BIC e guadagno di chiusura |
DM_RAZOR_FB | NFW + core da feedback (legacy) | log r_core | Il feedback può creare un core interno; approssimato con una scala di core a un parametro | ≤1 nuovo parametro; stessa cornice di chiusura/controllo negativo; il miglioramento RC-only non è l'unico obiettivo |
DM_HIER_CMSCAT | Dispersione c–M gerarchica + prior | σ_logc(hier) | Una forma gerarchica più standard c_i∼logN(c(M_i),σ_logc); influenza il posteriore congiunto RC e GGL | Prior esplicito; c_i latente marginalizzato; resta a bassa dimensionalità e verificabile |
DM_CORE1P | Proxy di core a 1 parametro (ispirato a coreNFW/DC14) | log r_core | Usa un proxy di core a un parametro per l'effetto principale del feedback barionico, evitando dettagli di formazione stellare ad alta dimensionalità | Cita letteratura standard; ≤1 nuovo parametro; legato al test di chiusura |
DM_RAZOR_M | NFW + nuisance di calibrazione dello shear nel lensing | m_shear(GGL) | Assorbe una sistematica chiave sul lato del lensing debole con un parametro efficace, riducendo il rischio di trattare le sistematiche come fisica | Nuisance registrato esplicitamente; non può retroagire su RC; i risultati sono giudicati soprattutto dalla robustezza della chiusura |
DM_STD | Baseline DM standardizzata (HIER_CMSCAT + CORE1P + m) | σ_logc + log r_core (+ m_shear) | Porta le tre obiezioni più comuni in una baseline standardizzata ancora a bassa dimensionalità | Riporta insieme il registro dei parametri e i criteri di informazione; la chiusura è la metrica principale; usata come confronto difensivo DM più forte |
Tabella B1 | Scoreboard P1A (più grande è meglio; mantenuta dall'Appendice B del rapporto originale)
Ramo di modello (workspace) | Δk | Miglior logL_RC RC-only (Δ) | Forza di chiusura ΔlogL_closure (Δ) | Miglior logL_total congiunto (Δ) |
DM_RAZOR | 0 | -15702.654 (+0.000) | 122.205 (+0.000) | -27347.068 (+0.000) |
DM_RAZOR_SCAT | 1 | -15702.294 (+0.361) | 121.236 (-0.969) | -23153.311 (+4193.758) |
DM_RAZOR_AC | 1 | -15703.689 (-1.035) | 121.531 (-0.674) | -23982.557 (+3364.511) |
DM_RAZOR_FB | 1 | -15496.046 (+206.609) | 129.454 (+7.249) | -27478.531 (-131.463) |
DM_HIER_CMSCAT | 1 | -15702.644 (+0.010) | 121.978 (-0.227) | -23153.160 (+4193.908) |
DM_CORE1P | 1 | -15723.158 (-20.504) | 122.056 (-0.149) | -27336.258 (+10.810) |
DM_RAZOR_M | 0 (+m) | -15702.654 (+0.000) | 122.205 (+0.000) | -27340.451 (+6.617) |
DM_STD | 2 (+m) | -15832.203 (-129.549) | 105.690 (-16.515) | -22984.445 (+4362.623) |
EFT_BIN | 1 | -14631.537 (+1071.117) | 204.620 (+82.415) | -19001.142 (+8345.926) |
Come leggere la Tabella B1 (scoreboard P1A) |
• Δk: gradi di libertà appena aggiunti (un valore maggiore indica un modello più complesso; più complesso non significa automaticamente migliore). • Concentrarsi su due colonne: forza di chiusura ΔlogL_closure(Δ) (più grande significa maggiore auto-coerenza del trasferimento) e miglior logL_total congiunto(Δ) (il punteggio totale del fit congiunto). • Il valore tra parentesi, (Δ), è la differenza rispetto a DM_RAZOR, e rende più semplice il confronto diretto. |
• La domanda principale posta da questa tabella è se il vantaggio di chiusura scompaia dopo che la baseline DM è stata "ragionevolmente rafforzata". • Suggerimento di lettura: DM_STD migliora nettamente il punteggio congiunto, ma la sua forza di chiusura diminuisce; EFT_BIN resta comunque più alto nella forza di chiusura. |
In una frase: entro questo insieme a bassa dimensionalità e verificabile di potenziamenti DM, migliorare il fit congiunto non produce automaticamente una chiusura più forte; la chiusura, cioè la trasferibilità, resta il criterio chiave. |
7 | Come leggere i risultati principali?
7.1 Fit congiunto: su entrambi i dataset, il punteggio del confronto principale EFT è più alto
La Tabella S1a e la Figura S4 mostrano che, con gli stessi dati, la stessa mappatura condivisa e una scala di parametri grossomodo simile, la famiglia EFT ha un ΔlogL_total congiunto di 1155–1337 rispetto a DM_RAZOR. Un lettore generale può leggerlo così: con la stessa regola di punteggio applicata a RC e GGL insieme, i modelli EFT del confronto principale ricevono un punteggio totale più alto.
7.2 Test di chiusura: ciò che P1 vuole soprattutto sottolineare è la "trasferibilità"
Una forza di chiusura elevata significa che i parametri inferiti solo da RC possono prevedere meglio GGL senza guardare di nuovo GGL. Nel rapporto P1, il ΔlogL_closure di EFT è 172–281, mentre DM_RAZOR è 127. Questo risultato conta più del dire che "ogni modello adatta bene i propri dati", perché limita la libertà del modello sul secondo dataset.
7.3 Controllo negativo: perché il "collasso del segnale" è una buona cosa?
Dopo che P1 mescola casualmente la corrispondenza di raggruppamento RC-bin→GGL-bin, il segnale di chiusura EFT scende nell'intervallo 6–23. Per un lettore generale, questo passaggio è come un controllo anti-trucco: se il vantaggio di chiusura fosse prodotto soltanto da codice, unità, gestione della covarianza o caso nel fitting, il vantaggio potrebbe restare anche con una corrispondenza mescolata. Invece il vantaggio reale collassa, mostrando che dipende dalla mappatura corretta.
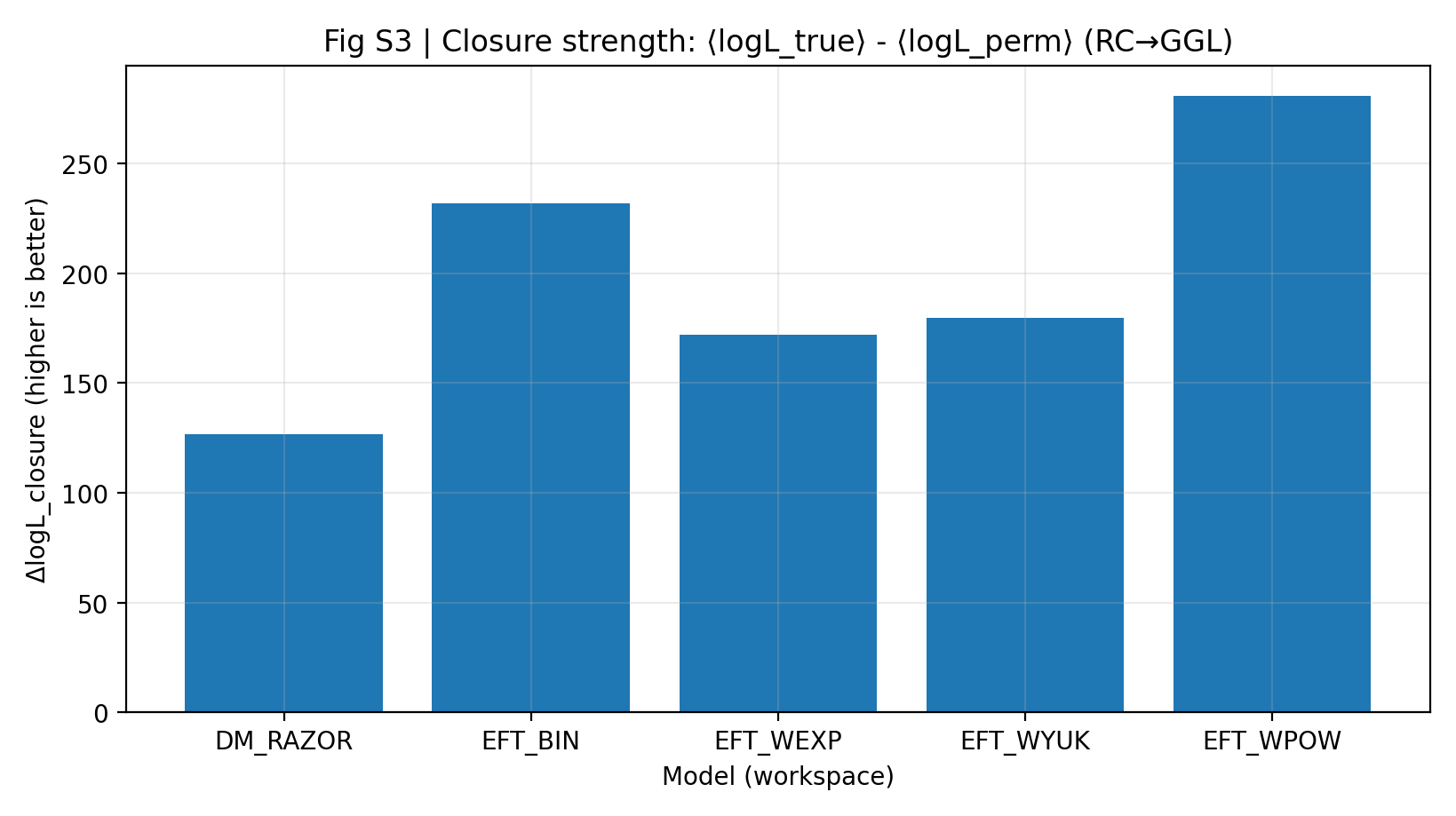
Figura S3 | Forza di chiusura (più grande è meglio): vantaggio medio di log-verosimiglianza per la previsione RC-only → GGL.
Come leggere questa figura |
Questa figura è il nucleo di P1. Quanto più alta è la barra, tanto meglio l'informazione appresa da RC si trasferisce a GGL. |
La famiglia EFT è complessivamente più alta di DM_RAZOR, indicando una chiusura EFT tra sonde più forte nell'esperimento "imparare prima RC, poi prevedere GGL". |
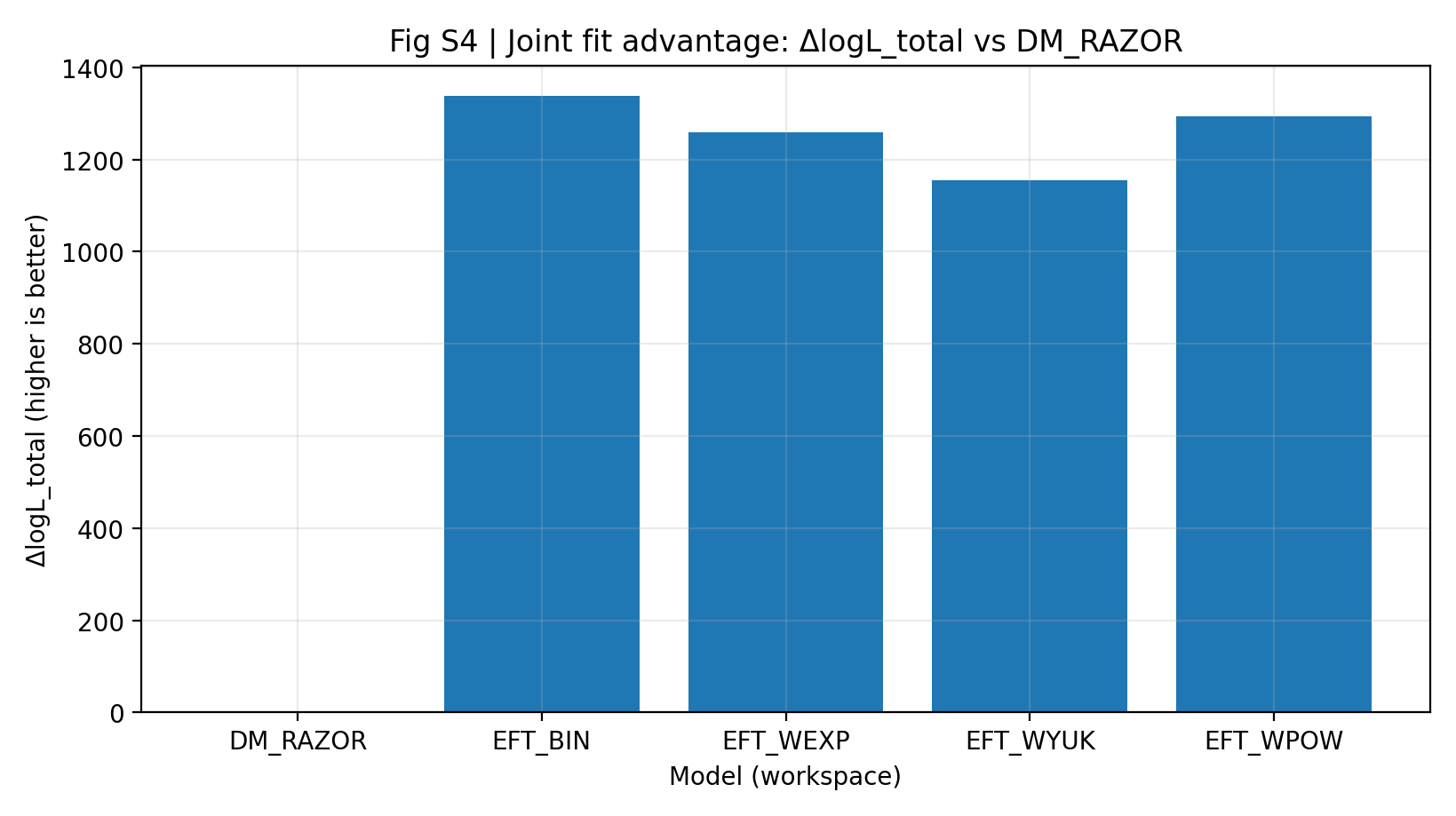
Figura S4 | Vantaggio del fit congiunto (più grande è meglio): miglior logL_total RC+GGL rispetto a DM_RAZOR.
Come leggere questa figura |
Questa figura mostra il punteggio totale dopo aver combinato RC e GGL. |
Tutti i modelli EFT sono ben sopra 0, indicando che il vantaggio EFT nel confronto principale non è un effetto locale di un singolo punto, ma uno schema complessivo nell'analisi congiunta. |
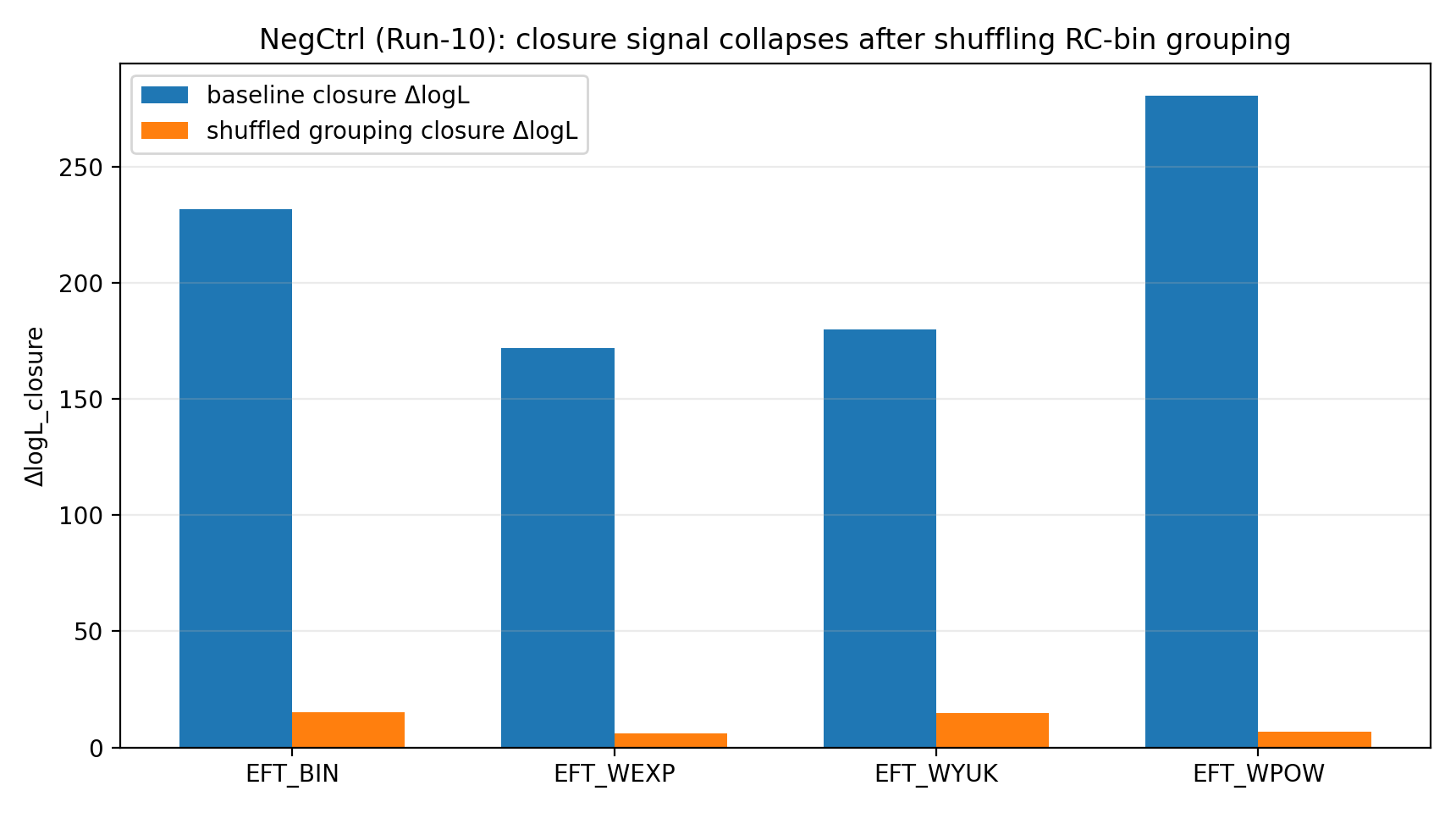
Figura R1 | Controllo negativo: il segnale di chiusura cala nettamente dopo il mescolamento del raggruppamento.
Come leggere questa figura |
Questa figura mostra che, una volta disturbata la corretta relazione di binning RC↔GGL, il segnale di chiusura cala nettamente. |
Questo fa apparire il risultato P1 più come una coerenza reale nella mappatura tra dati che come una coincidenza numerica ottenibile con mappature arbitrarie. |
8 | Robustezza e controlli: come evita P1 di essere "solo un fit dall'aspetto convincente"?
La contestazione più facile da sollevare contro un rapporto tecnico è chiedere se il vantaggio derivi da una sola impostazione del rumore, da un solo taglio sui dati delle regioni centrali, da un solo trattamento della covarianza o da overfitting. P1 risponde con più stress test.
Tabella 2 | Come leggere i test di robustezza e i controlli negativi di P1
Test | Preoccupazione che cerca di escludere | Come leggerlo |
σ_int scan | Se RC contiene ulteriore dispersione ignota, la conclusione resta stabile? | Dopo aver rilassato gli errori RC, il ranking EFT e la scala del vantaggio restano stabili. |
R_min scan | Se le regioni centrali delle galassie non sono pienamente affidabili, la conclusione resta stabile? | Dopo il taglio delle regioni centrali, EFT mantiene ancora un vantaggio positivo. |
cov-shrink scan | Se la stima della covarianza GGL è incerta, la conclusione resta stabile? | Dopo lo shrinkage della covarianza verso la diagonale, il vantaggio non è sensibile. |
Scala di ablazione | EFT si basa su complessità non necessaria per forzare il fit? | L'EFT_BIN completo è supportato dai criteri di informazione. |
Previsione LOO su dati tenuti fuori | Il modello spiega soltanto dati che ha già visto? | Dopo aver escluso un GGL-bin, il modello mostra ancora una forte capacità di generalizzazione. |
Shuffle degli RC-bin | La chiusura proviene dalla mappatura reale? | La chiusura cala dopo il mescolamento del raggruppamento, sostenendo la dipendenza dalla mappatura. |
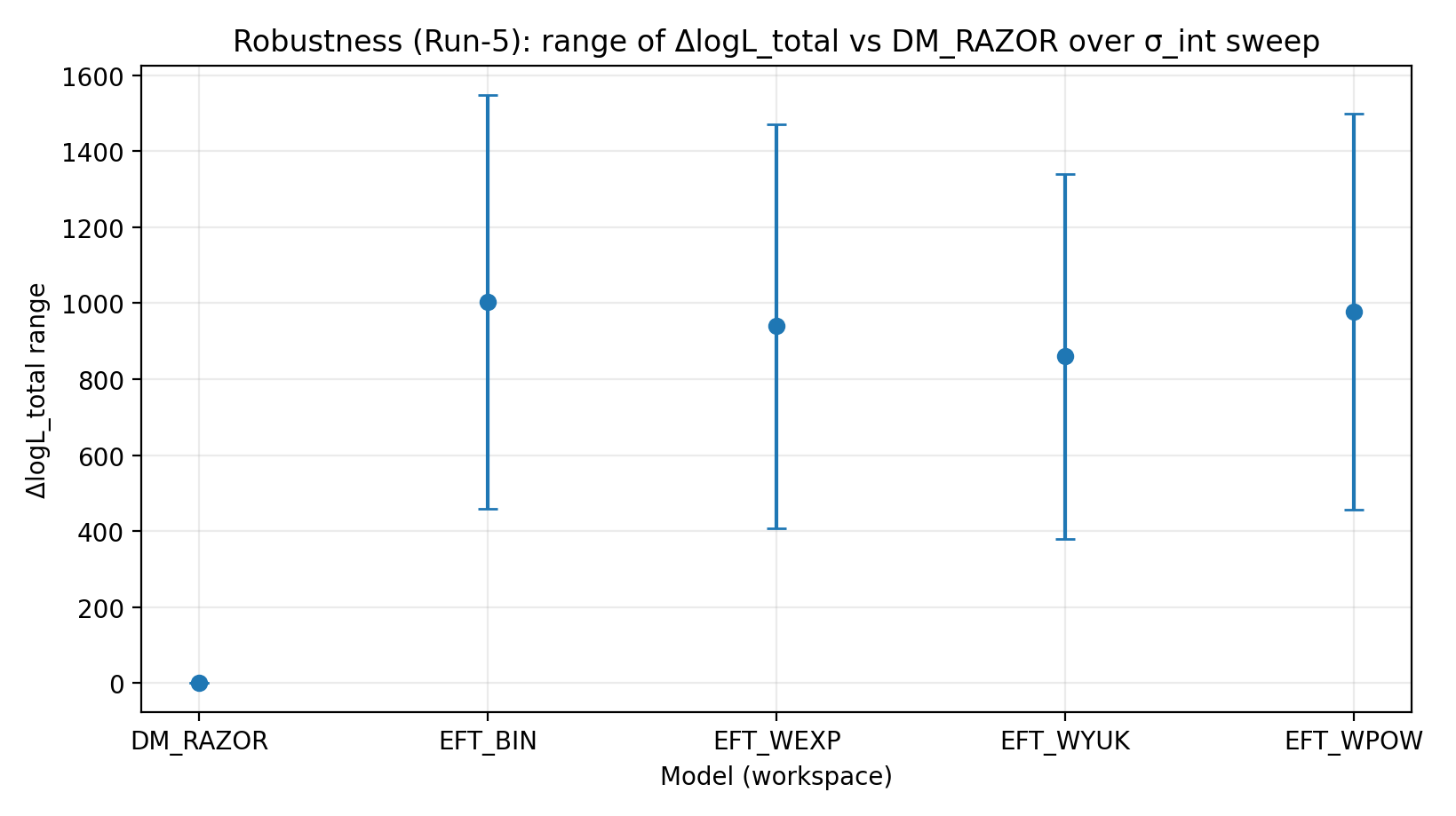
Figura R2 | Intervallo di ΔlogL_total nello scan σ_int (più grande è meglio).
Come leggere questa figura |
Verifica se il vantaggio di EFT resta dopo cambiamenti nella dispersione intrinseca RC assunta. |
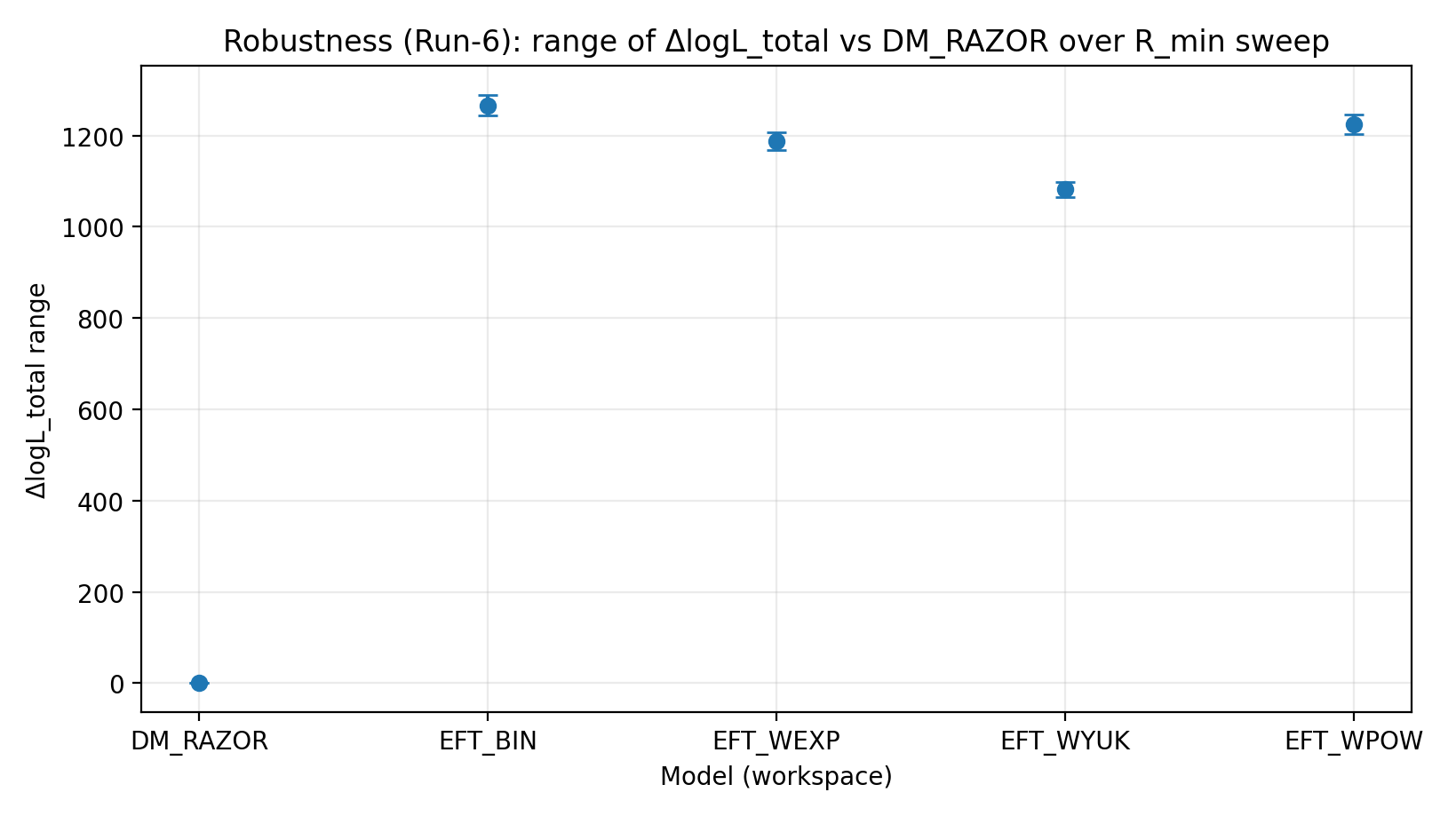
Figura R3 | Intervallo di ΔlogL_total nello scan R_min (più grande è meglio).
Come leggere questa figura |
Verifica se il vantaggio di EFT resta stabile dopo il taglio di regioni centrali complesse. |
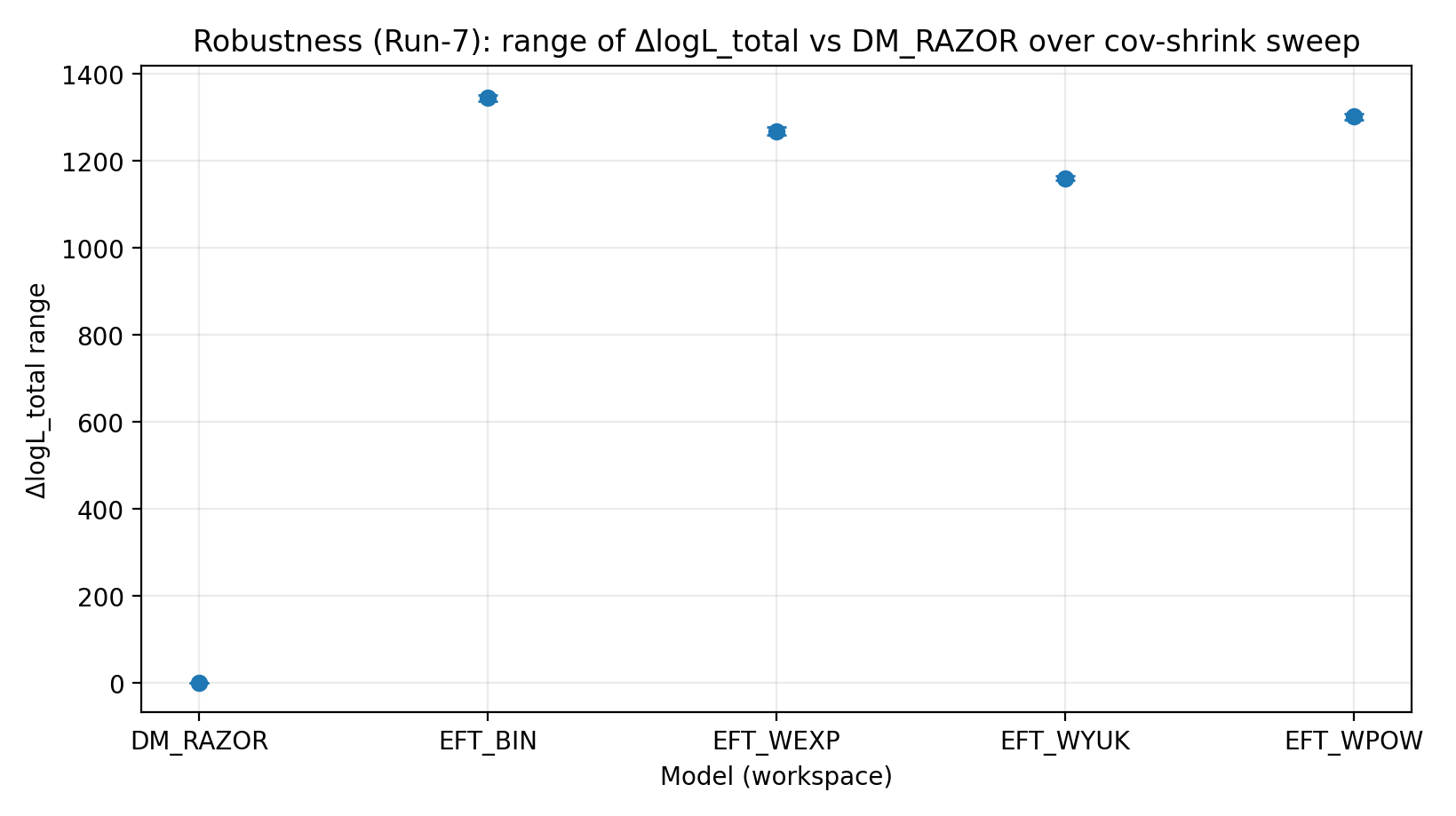
Figura R4 | Intervallo di ΔlogL_total nello scan cov-shrink (più grande è meglio).
Come leggere questa figura |
Verifica se il ranking è sensibile a cambiamenti nel trattamento della covarianza del lensing debole. |
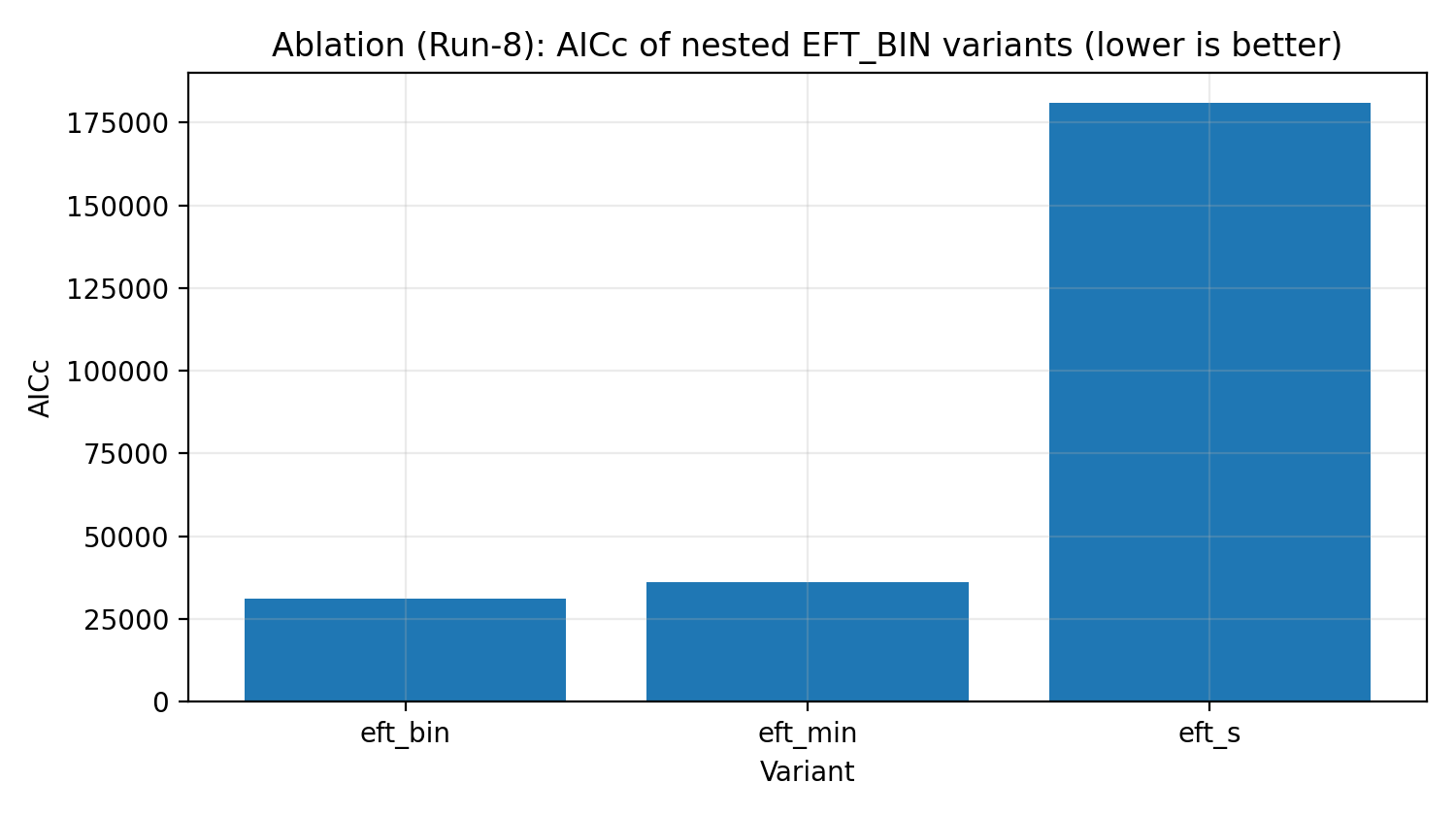
Figura R5 | Scala di ablazione EFT_BIN (AICc, più piccolo è meglio).
Come leggere questa figura |
Verifica se l'EFT_BIN completo è necessario per spiegare i dati, invece di aggiungere soltanto parametri superflui. |
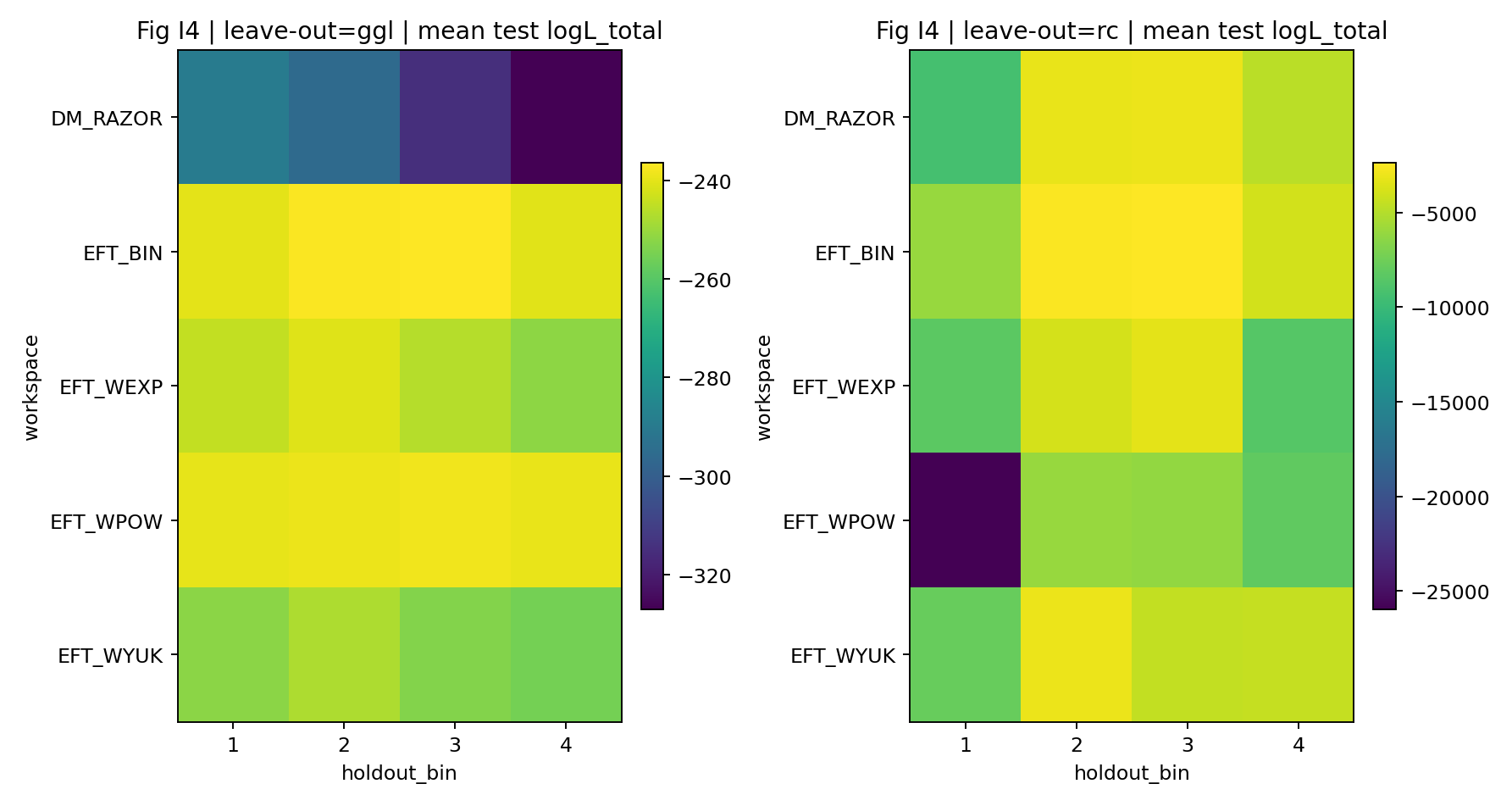
Figura R6 | LOO: distribuzione della log-verosimiglianza per bin tenuti fuori.
Come leggere questa figura |
Verifica se il modello conserva capacità predittiva su GGL-bin non visti. |
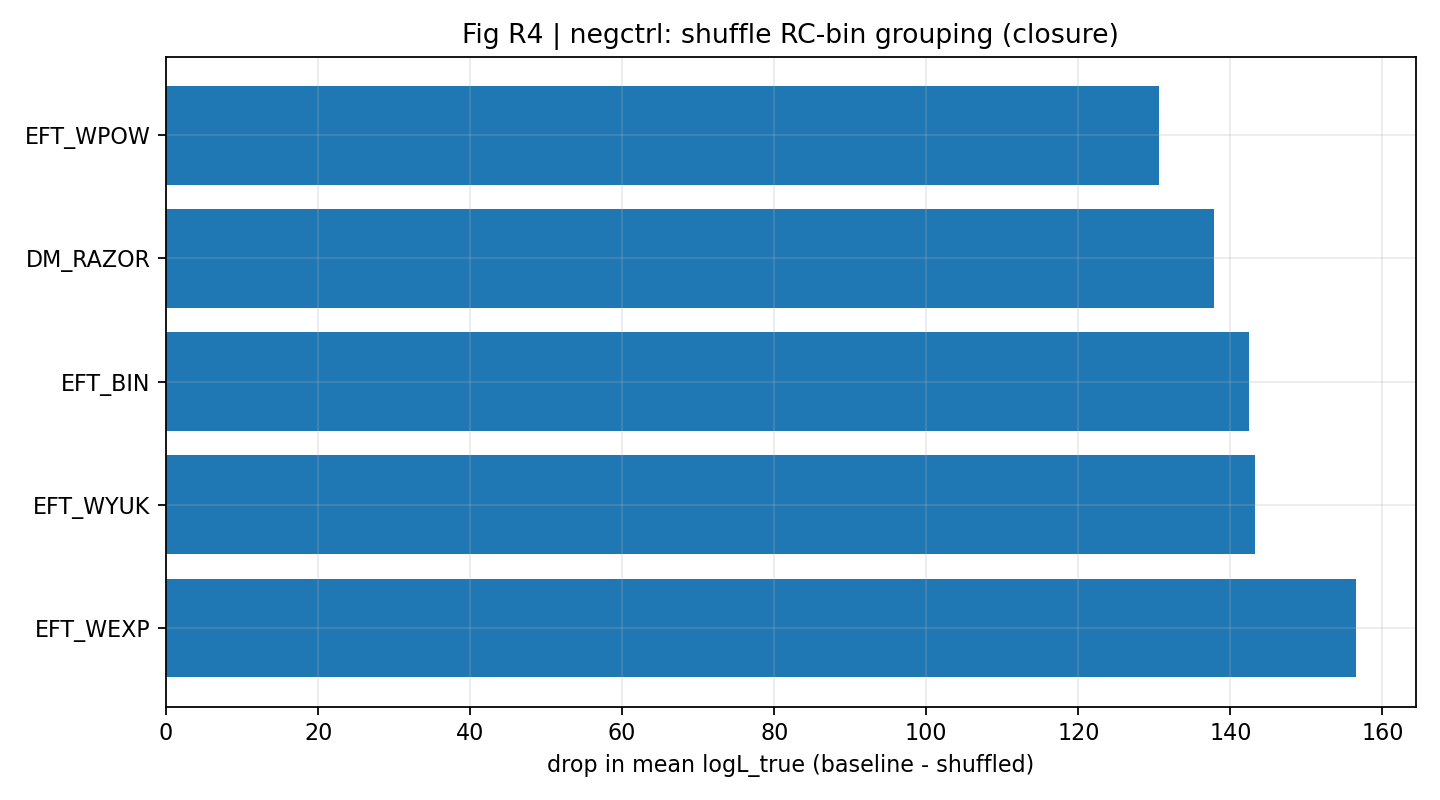
Figura R7 | Controllo negativo: la mappatura mescolata causa un chiaro calo della media logL_true di chiusura.
Come leggere questa figura |
Mostra inoltre, dal punto di vista della media logL_true, che la chiusura dipende dalla corretta mappatura tra dati. |
9 | P1A: perché "più modelli DM in appendice" è una correzione chiave
Questa sezione non chiede: "EFT ha battuto soltanto una baseline DM_RAZOR minima?" Chiede se le conclusioni del test di chiusura e del fit congiunto cambiano quando la baseline DM viene rafforzata entro un registro di parametri a bassa dimensionalità, riproducibile e chiaramente documentato (P1A). In altre parole, P1A mira a ridurre l'obiezione secondo cui "è stata scelta solo una baseline DM troppo debole" e sposta la discussione verso la domanda: il comportamento di chiusura resta diverso sotto un insieme di potenziamenti DM verificabili?
P1A non è progettato per esaurire tutte le possibili modellizzazioni degli aloni LambdaCDM, né trasforma il lato DM in un fitter ad alta dimensionalità e non verificabile. Seleziona potenziamenti a bassa dimensionalità e riproducibili con un registro chiaro dei parametri: dispersione della concentrazione, contrazione adiabatica, core da feedback, prior gerarchico sulla dispersione c–M, proxy di core a un parametro, nuisance di calibrazione dello shear nel lensing e la baseline combinata DM_STD.
Lettura principale di P1A |
Tra i tre rami legacy, solo feedback/core produce un piccolo aumento netto della forza di chiusura; SCAT e AC non producono guadagni netti di chiusura. |
DM_HIER_CMSCAT, DM_RAZOR_M e DM_CORE1P hanno un effetto molto ridotto sulla forza di chiusura o non mostrano un miglioramento netto significativo. |
DM_STD può migliorare sensibilmente il logL congiunto, ma la sua forza di chiusura diminuisce, suggerendo che migliori soprattutto la flessibilità del fit congiunto e non la potenza predittiva di trasferimento RC→GGL. |
EFT_BIN conserva ancora una forza di chiusura più alta e un vantaggio di fit congiunto nella Tabella B1 di P1A; quindi la tesi centrale di P1 non dovrebbe essere ridotta a "ha battuto solo il minimo DM_RAZOR". |
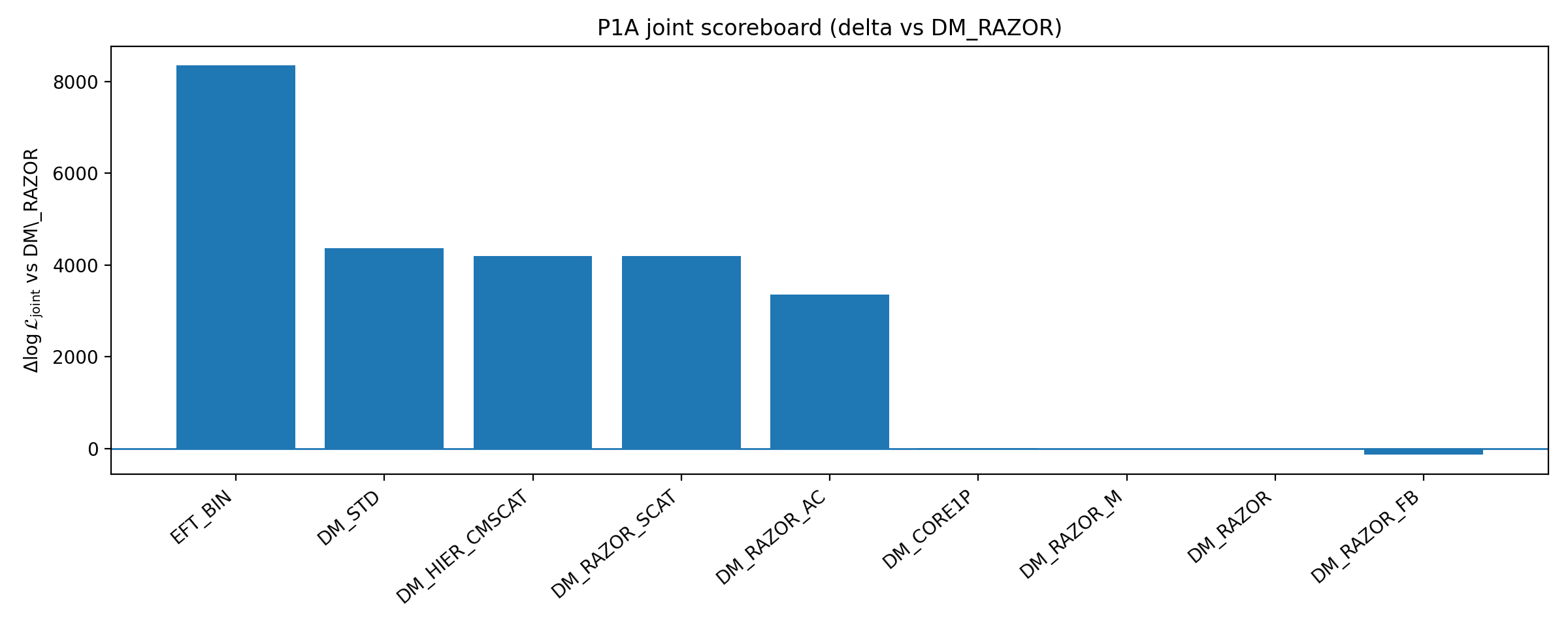
Figura B1 | Scoreboard P1A: chiusura e ΔlogL congiunto rispetto alla baseline (più grande è meglio).
Come leggere questa figura |
Questa figura mostra la prestazione di più rami di potenziamento DM rispetto alla baseline. |
Il suo significato non è "tutta la DM è esclusa", ma questo: entro i potenziamenti DM a bassa dimensionalità e verificabili selezionati da P1A, rafforzare DM non rimuove il vantaggio di chiusura di EFT_BIN. |
10 | Perché l'esperimento P1 è importante
10.1 Significato metodologico: porre la "chiusura tra sonde" sopra il "fit a singola sonda"
La teoria su scala galattica può facilmente bloccarsi sulla domanda se un modello riesca ad adattare una particolare serie di curve di rotazione. P1 alza la domanda di un livello: i parametri appresi da RC possono prevedere il lensing debole senza ritararsi su GGL? Così P1 passa da una "gara di fit" a un "test di previsione per trasferimento".
10.2 Significato di trasparenza: trattare la catena di riproducibilità come parte del risultato
Un contributo importante di P1 è che rilascia insieme dati, tabelle e figure, etichette delle run, controlli negativi, pacchetto di riproduzione e catena di audit. Questo conta sia per i sostenitori sia per i critici: la discussione può tornare agli stessi dati pubblici, alla stessa mappatura, agli stessi script e alle stesse metriche, invece di confrontare slogan.
10.3 Significato fisico: uno stress test forte per le direzioni di "gravità senza materia oscura"
Nelle direzioni di gravità senza materia oscura, molti modelli possono spiegare una parte delle curve di rotazione o della RAR. Il compito più difficile è superare anche le letture di lensing debole e mostrare, sotto controlli negativi, che il segnale dipende dalla mappatura corretta. P1 conta perché colloca la risposta gravitazionale media di EFT in un protocollo simile a un esame esterno: RC è il terreno di addestramento, GGL è il campo di trasferimento e lo shuffle è il campo anti-trucco.
10.4 È un esperimento importante per il campo della "gravità senza materia oscura"?
Detto con cautela: se l'elaborazione dei dati, il pacchetto di riproduzione e il protocollo di chiusura di P1 reggono alla revisione esterna, allora P1 può essere considerato un esperimento di chiusura RC+GGL da prendere sul serio nelle direzioni di gravità senza materia oscura / gravità modificata. La sua importanza non sta nello slogan "la materia oscura è stata rovesciata", ma nel fornire un criterio tra sonde che può essere replicato, contestato ed esteso.
Esistono già quadri di previsione-chiusura RC+GGL allo stesso livello? |
Esistono quadri e tradizioni osservative rilevanti: MOND/RAR organizza bene molti fenomeni delle curve di rotazione; il lavoro KiDS-1000 sulla RAR da lensing debole ha confrontato anche MOND, la gravità emergente di Verlinde e modelli LambdaCDM; LambdaCDM può inoltre spiegare alcuni fenomeni di lensing debole e dinamica tramite connessioni galassia–alone, aloni di gas e modellazione del feedback. |
Ma la tesi precisa di P1 non è che "nessun altro quadro al mondo può spiegare RC+GGL". Piuttosto, sotto il protocollo pubblico proprio di P1 — mappatura fissa, chiusura RC-only→GGL, controlli negativi shuffle, registro dei parametri e stress test multi-DM P1A — EFT riporta una prestazione di chiusura più forte. |
In altre parole, la parte di P1 che più merita test esterni è il suo protocollo di confronto concreto e riproducibile. Un passo successivo molto utile sarebbe verificare se MOND/RAR, LambdaCDM/HOD, simulazioni idrodinamiche o altri quadri di gravità modificata possano raggiungere punteggi di chiusura uguali o superiori sotto lo stesso protocollo. |
11 | Che cosa può concludere P1, e che cosa non può concludere?
Tabella 3 | Confini delle conclusioni di P1
Si può concludere | Sotto i dati RC+GGL, la mappatura fissa e il protocollo di confronto principale di P1, la famiglia EFT ha punteggi di fit congiunto e forza di chiusura più alti del minimo DM_RAZOR. |
Si può concludere | Entro l'intervallo di potenziamenti DM a bassa dimensionalità e verificabili di P1A, più potenziamenti DM non eliminano il vantaggio di chiusura di EFT_BIN. |
Si può concludere | Il controllo negativo shuffle mostra che il segnale di chiusura dipende dalla corretta mappatura tra dati e non è ottenibile con mappature arbitrarie. |
Non si può concludere | Non si può dire che P1 abbia rovesciato tutti i modelli di materia oscura. P1A continua a non esaurire non sfericità, dipendenza ambientale, connessioni galassia–alone complesse, feedback ad alta dimensionalità o simulazioni cosmologiche complete. |
Non si può concludere | Non si può dire che il quadro EFT completo sia stato dimostrato da primi principi. P1 testa solo lo strato fenomenologico della risposta gravitazionale media. |
Non si può concludere | Non si può dire che tutte le sistematiche siano state escluse. P1 fornisce evidenza di robustezza solo entro gli stress test elencati e l'ambito dell'audit. |
12 | Domande frequenti dei lettori generali
D1: Si sta dicendo che "la materia oscura non esiste"?
No. Le conclusioni di P1 devono restare limitate ai dati, al protocollo e ai modelli di confronto usati qui. P1A va oltre il minimo DM_RAZOR, ma continua a non rappresentare tutti i possibili modelli di materia oscura.
D2: Si sta dicendo che "EFT è stata dimostrata"?
Ancora no. P1 testa EFT come parametrizzazione della risposta gravitazionale media e mostra prestazioni più forti nella chiusura RC→GGL; il meccanismo microscopico e la teoria completa non sono la conclusione di P1.
D3: Perché non riportare direttamente un valore di significatività in σ?
P1 usa punteggi di verosimiglianza unificati, criteri di informazione e differenze di chiusura. ΔlogL è un vantaggio relativo sotto la stessa regola di punteggio; non equivale a un singolo valore σ.
D4: Perché mescolare RC-bin→GGL-bin?
Questo è un controllo negativo. Un segnale reale tra sonde dovrebbe dipendere dalla mappatura corretta; se restasse altrettanto forte dopo lo shuffle, suggerirebbe invece un possibile bias di implementazione o un falso segnale statistico.
D5: Che cosa dovrebbe fare P1 dopo?
Estendere lo stesso protocollo a più dati, più confronti DM, sistematiche più complesse e più quadri di gravità modificata, soprattutto in modi che consentano a team esterni di ripetere il test con la stessa metrica di chiusura.
13 | Mini glossario
Tabella 4 | Mini glossario
Termine | Spiegazione in una frase |
Curva di rotazione (RC) | La relazione raggio–velocità di rotazione in un disco galattico, usata per inferire la gravità effettiva all'interno del disco. |
Lensing debole (GGL) | Una misura della distribuzione media di gravità/massa attorno alle galassie in primo piano tramite la distorsione statistica delle forme delle galassie di sfondo. |
Test di chiusura | Usa il posteriore RC per prevedere GGL, poi lo confronta con il controllo negativo prodotto dalla mappatura mescolata. |
Controllo negativo | Rompe deliberatamente una struttura chiave per vedere se il segnale scompare; serve a escludere falsi segnali. |
Alone NFW | Un profilo di densità per aloni di materia oscura, comunemente usato nei modelli di materia oscura fredda. |
Relazione c–M | La relazione tra la concentrazione c e la massa M di un alone di materia oscura; consentire o meno la dispersione influisce sulla flessibilità del modello. |
DM_STD | Il ramo di stress test DM standardizzato in P1A, che combina più potenziamenti DM a bassa dimensionalità e un termine nuisance di lensing. |
ΔlogL | La differenza di log-verosimiglianza tra due modelli sotto la stessa regola di punteggio; un valore positivo significa che il primo è migliore. |
Covarianza | Una descrizione matriciale delle correlazioni tra punti dati; i dati di lensing debole richiedono di solito la covarianza completa. |
14 | Percorso di lettura suggerito e punti d'ingresso per le citazioni
1. Leggere prima le sezioni 0–2 di questa guida per stabilire la domanda di P1 e il ruolo deliberatamente prudente di EFT in P1.
2. Poi leggere la Figura S3, la Figura S4 e le Tabelle S1a/S1b per capire forza di chiusura, fit congiunto e controlli negativi.
3. Se si teme che la "baseline DM sia troppo debole", andare direttamente alla Sezione 9 e alla Tabella B1 / Figura B1.
4. Per la verifica tecnica, tornare al rapporto tecnico P1 v1.1, al Supplemento Tabelle e Figure e al full_fit_runpack.
Principali punti d'ingresso agli archivi |
Rapporto tecnico P1 (livello di release, Concept DOI): 10.5281/zenodo.18526334 |
Pacchetto completo di riproduzione P1 (Concept DOI): 10.5281/zenodo.18526286 |
Knowledge base strutturata EFT (opzionale, Concept DOI): 10.5281/zenodo.18853200 |
Nota di licenza: il rapporto tecnico usa CC BY-NC-ND 4.0; il pacchetto completo di riproduzione usa CC BY 4.0 (fare riferimento al rapporto tecnico e agli archivi Zenodo come fonti autorevoli). |
15 | Riferimenti e contesto esterno
McGaugh, S. S., Lelli, F., & Schombert, J. M. (2016). The Radial Acceleration Relation in Rotationally Supported Galaxies. Physical Review Letters, 117, 201101. DOI: 10.1103/PhysRevLett.117.201101.
Famaey, B., & McGaugh, S. S. (2012). Modified Newtonian Dynamics (MOND): Observational Phenomenology and Relativistic Extensions. Living Reviews in Relativity, 15, 10. DOI: 10.12942/lrr-2012-10.
Brouwer, M. M., Oman, K. A., Valentijn, E. A., et al. (2021). The weak lensing radial acceleration relation: Constraining modified gravity and cold dark matter theories with KiDS-1000. Astronomy & Astrophysics, 650, A113. DOI: 10.1051/0004-6361/202040108.
Mistele, T., McGaugh, S., Lelli, F., Schombert, J., & Li, P. (2024). Indefinitely Flat Circular Velocities and the Baryonic Tully-Fisher Relation from Weak Lensing. The Astrophysical Journal Letters, 969, L3 / arXiv:2406.09685.
Bullock, J. S., & Boylan-Kolchin, M. (2017). Small-Scale Challenges to the LambdaCDM Paradigm. Annual Review of Astronomy and Astrophysics, 55, 343–387. DOI: 10.1146/annurev-astro-091916-055313.
Lelli, F., McGaugh, S. S., & Schombert, J. M. (2016). SPARC: Mass Models for 175 Disk Galaxies with Spitzer Photometry and Accurate Rotation Curves. The Astronomical Journal, 152, 157. DOI: 10.3847/0004-6256/152/6/157.
Navarro, J. F., Frenk, C. S., & White, S. D. M. (1997). A Universal Density Profile from Hierarchical Clustering. Astrophysical Journal, 490, 493.
Dutton, A. A., & Macciò, A. V. (2014). Cold dark matter haloes in the Planck era: evolution of structural parameters for NFW haloes. Monthly Notices of the Royal Astronomical Society, 441, 3359–3374.